
加减乘除
注意俩个问题

对空值处理


inf = infinity(无穷大)
pd.options.mode.use_inf_as_na = True # 默认为Flase设置之后无穷大的值就会变为NaN

#%%
import pandas as pd
import numpy as np
# pd.options.mode.use_inf_as_na = True
#%%
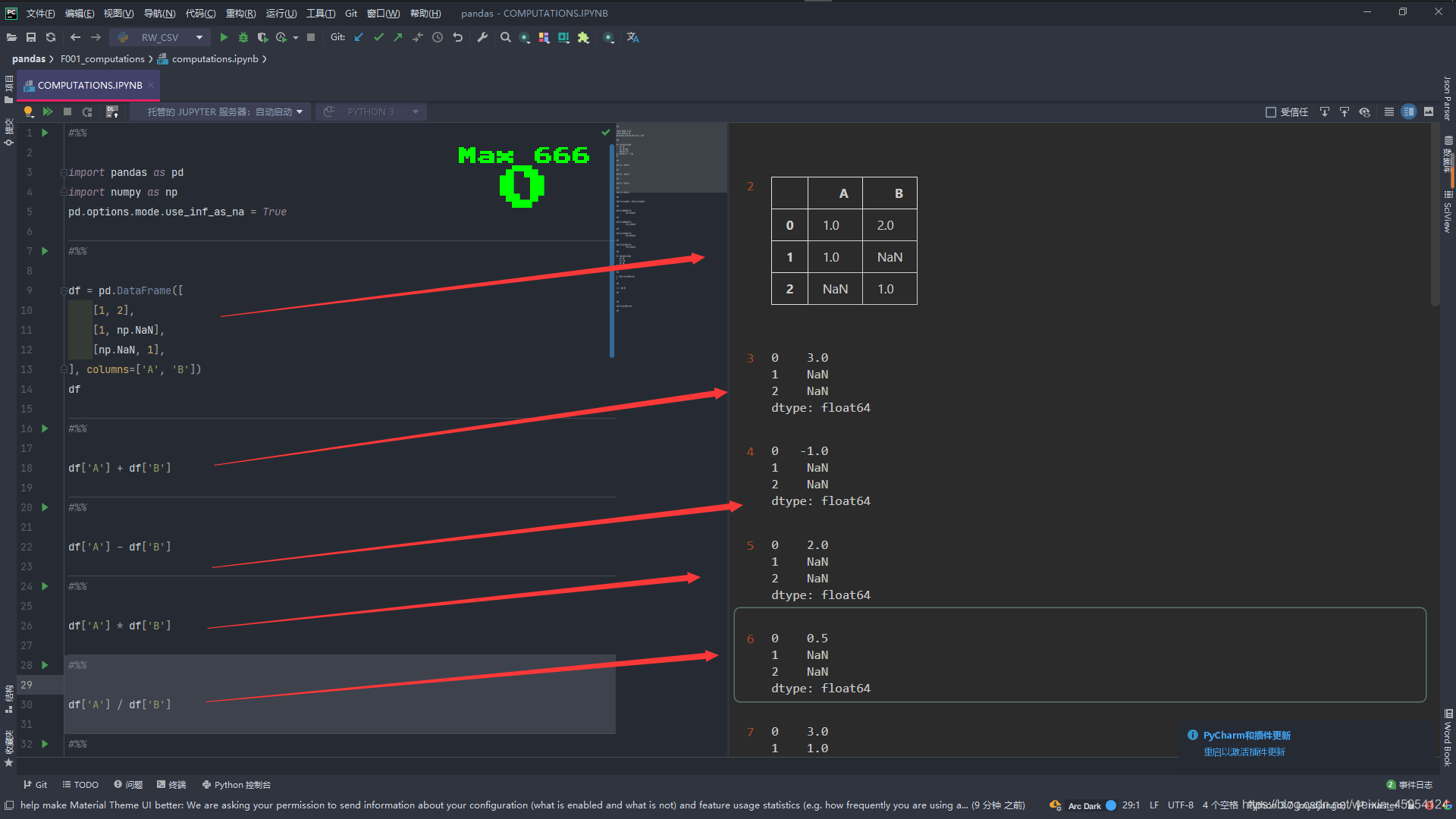
df = pd.DataFrame([
[1, 2],
[1, np.NaN],
[np.NaN, 1],
], columns=['A', 'B'])
df
#%%
# 不是我们想要的结果 展示的是NaN
df['A'] + df['B']
#%%
# 不是我们想要的结果 展示的是NaN
df['A'] - df['B']
#%%
# 不是我们想要的结果 展示的是NaN
df['A'] * df['B']
#%%
# 不是我们想要的结果 展示的是NaN
df['A'] / df['B']
使用fillna(0)方法 补充空值为0
使用add()是 +
使用sub()是 -
使用mul()是 *
使用div()是 /
#%%
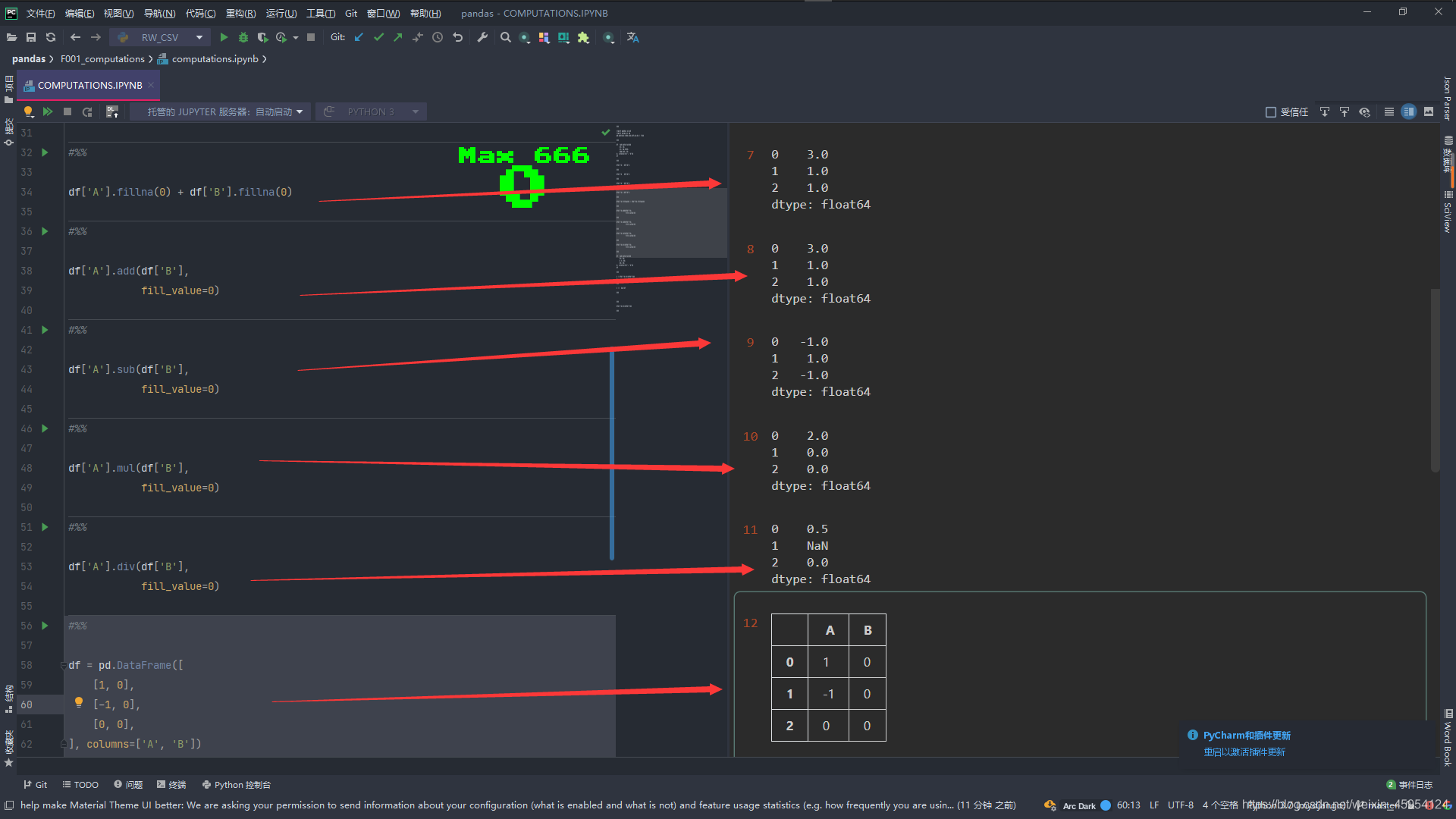
# 我们使用fillna()方法发现 NaN没有了
df['A'].fillna(0) + df['B'].fillna(0)
#%%
# 使用add()是 + 都会把空值当0
df['A'].add(df['B'],
fill_value=0)
#%%
# 使用sub()是 - 都会把空值当0
df['A'].sub(df['B'],
fill_value=0)
#%%
# 使用mul()是 * 都会把空值当0
df['A'].mul(df['B'],
fill_value=0)
#%%
# 使用div()是 / 都会把空值当0 显示了无穷大
df['A'].div(df['B'],
fill_value=0)
#%%
df = pd.DataFrame([
[1, 0],
[-1, 0],
[0, 0],
], columns=['A', 'B'])
df
#%%
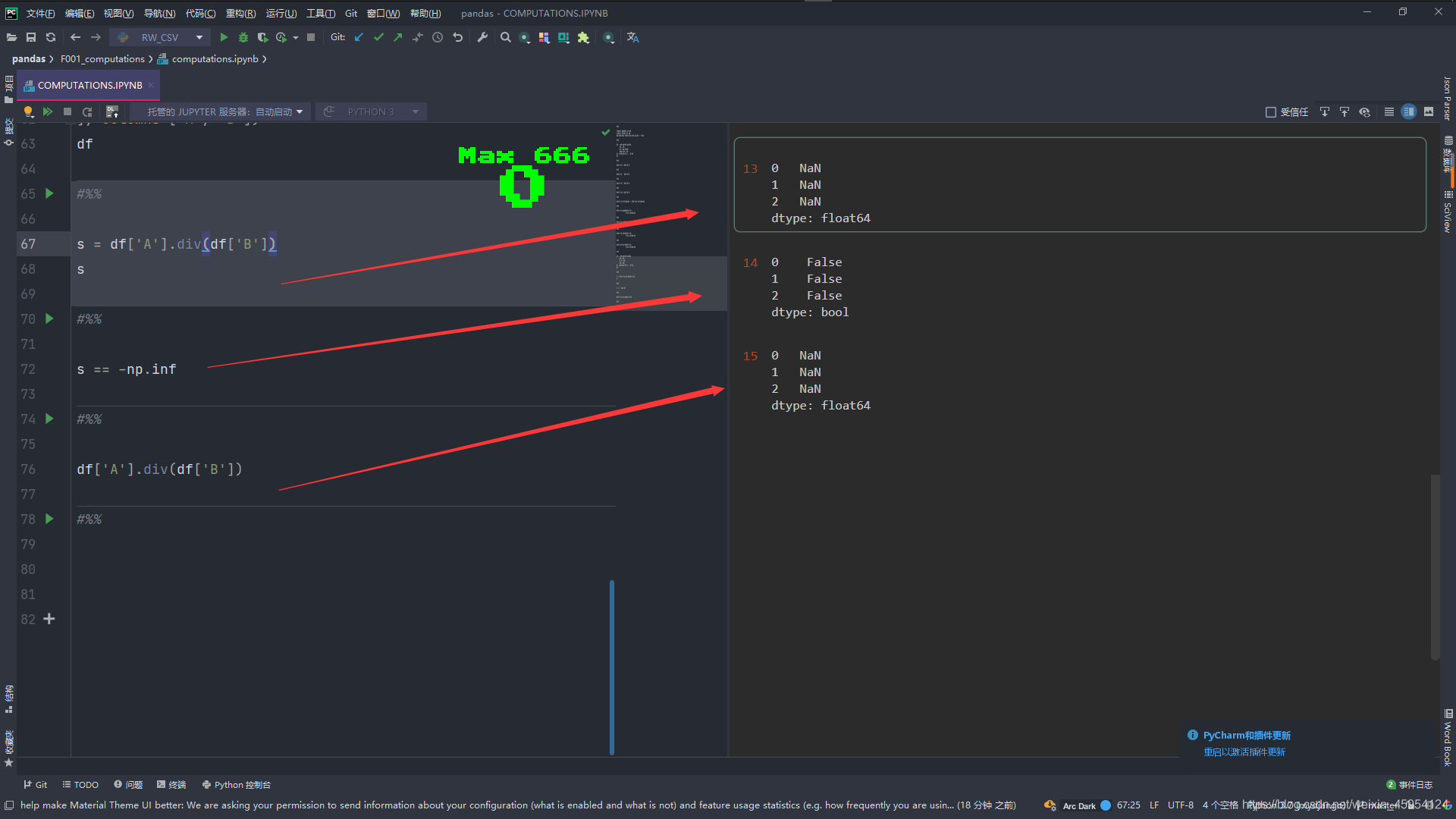
# 结果是 无穷大 负无穷大 NaN
s = df['A'].div(df['B'])
s
#%%
# True False False
# s == np.inf
# False True False
s == -np.inf
#%%
# 当我们取消注释 # pd.options.mode.use_inf_as_na = True 发现没有无穷大的展示了 都变为了NaN
df['A'].div(df['B'])
计算操作中 index 不对齐的情况
Series
这里演示加的方法 其它同理
#%% 计算操作中 Series 的 index 不对齐的情况
import pandas as pd
#%%
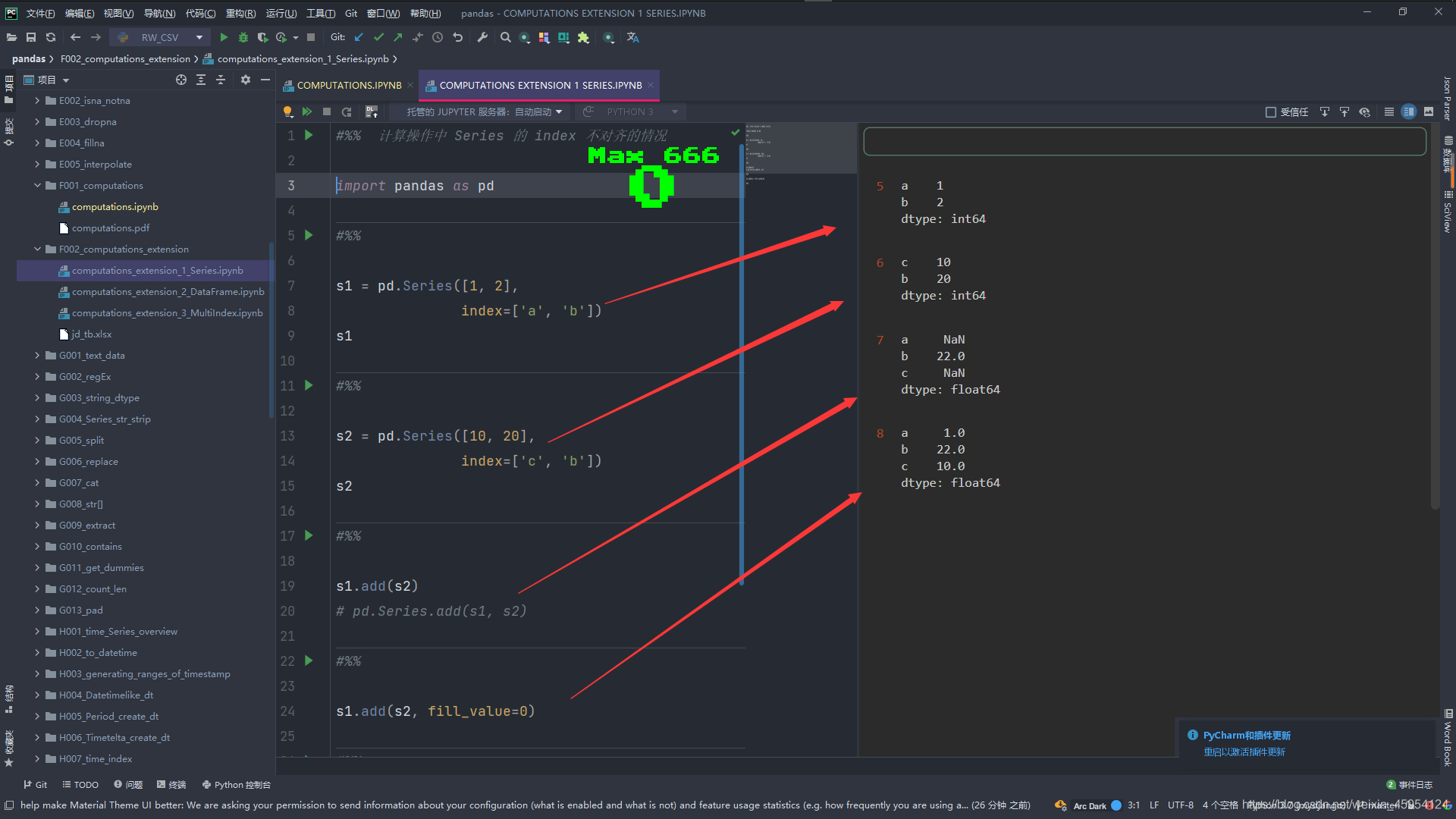
s1 = pd.Series([1, 2],
index=['a', 'b'])
s1
#%%
s2 = pd.Series([10, 20],
index=['c', 'b'])
s2
#%%
# 这俩种的调用发放都是一样的
# 这时候索引没对齐 展示的都是空值 NaN
s1.add(s2)
# pd.Series.add(s1, s2)
#%%
# 我们使用fill_value=0 让空值补为0 这样就是 1 + 0 和 10 + 0了结果就是 1 22 10
# 新的Series索引为俩个Series的并集
s1.add(s2, fill_value=0)
DataFrame
这里演示加的方法 其它同理
#%% .add .sub .mul .div
import pandas as pd
#%%
df1 = pd.DataFrame([
[1, 2],
[3, 4],
], columns=['A', 'B'],
index=['X', 'Y'])
df1
#%%
# 简单的相加 行列索引对齐就是 1+1 2+2 3+3 4+4
# df1.add(df1)
#%%
df2 = pd.DataFrame([
[10, 20],
[30, 40],
], columns=['C', 'B'],
index=['Z', 'Y'])
df2
#%%
# # 只有俩个索引一致 行B 列Y 只有[Y,B]有值 其它为NaN
df1.add(df2)
#%%
# 使用fill_value补充NaN为0 在进行运算
# 新的DataFrame索引取并集
df1.add(df2, fill_value=0)
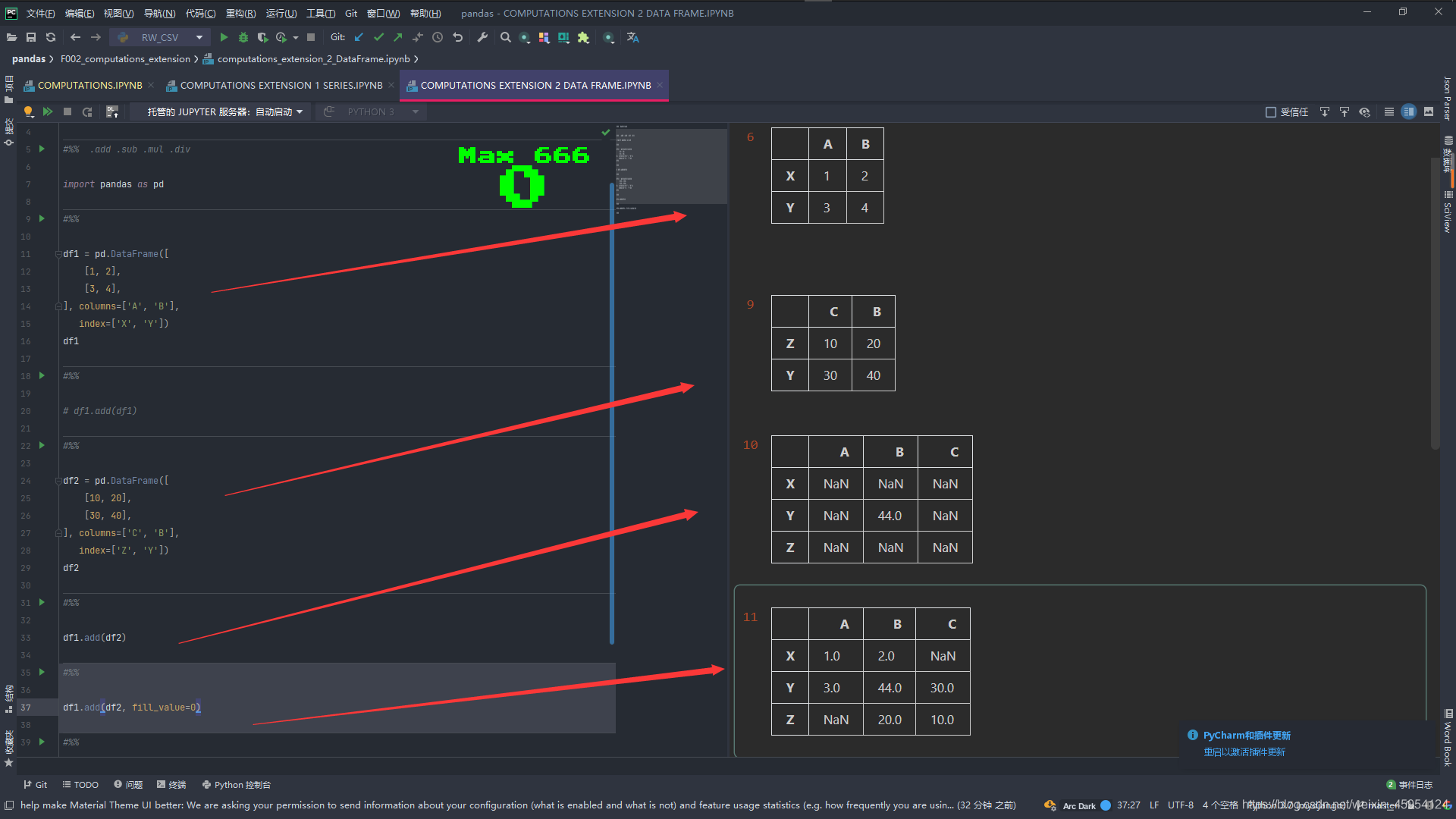
MultiIndex 多层索引
#%% 计算操作 MultiIndex 多层索引
import pandas as pd
#%%
df = pd.read_excel(
'jd_tb.xlsx',
header=[0, 1]
)
df
#%%
# 输出行索引
df.columns
#%%
# 销量加销量 1+4 5+7 结果是Series
# 注意格式 [()]
df[('京东', '销量')] + df[('淘宝', '销量')]
#%%
# 俩个DataFrame相机 结果就是DataFrame
df_total = df['京东'] + df['淘宝']
df_total
#%%
# 在上面在加一个索引 MultiIndex成为多层索引 注意格式传入[[]]
# df_total.columns是可迭代对象就可以
df_total.columns = pd.MultiIndex.from_product(
[
['总'],
df_total.columns
]
)
df_total
#%%
# 我们进行拼接 使用join 根据行索引进行左右拼接
df.join(df_total)
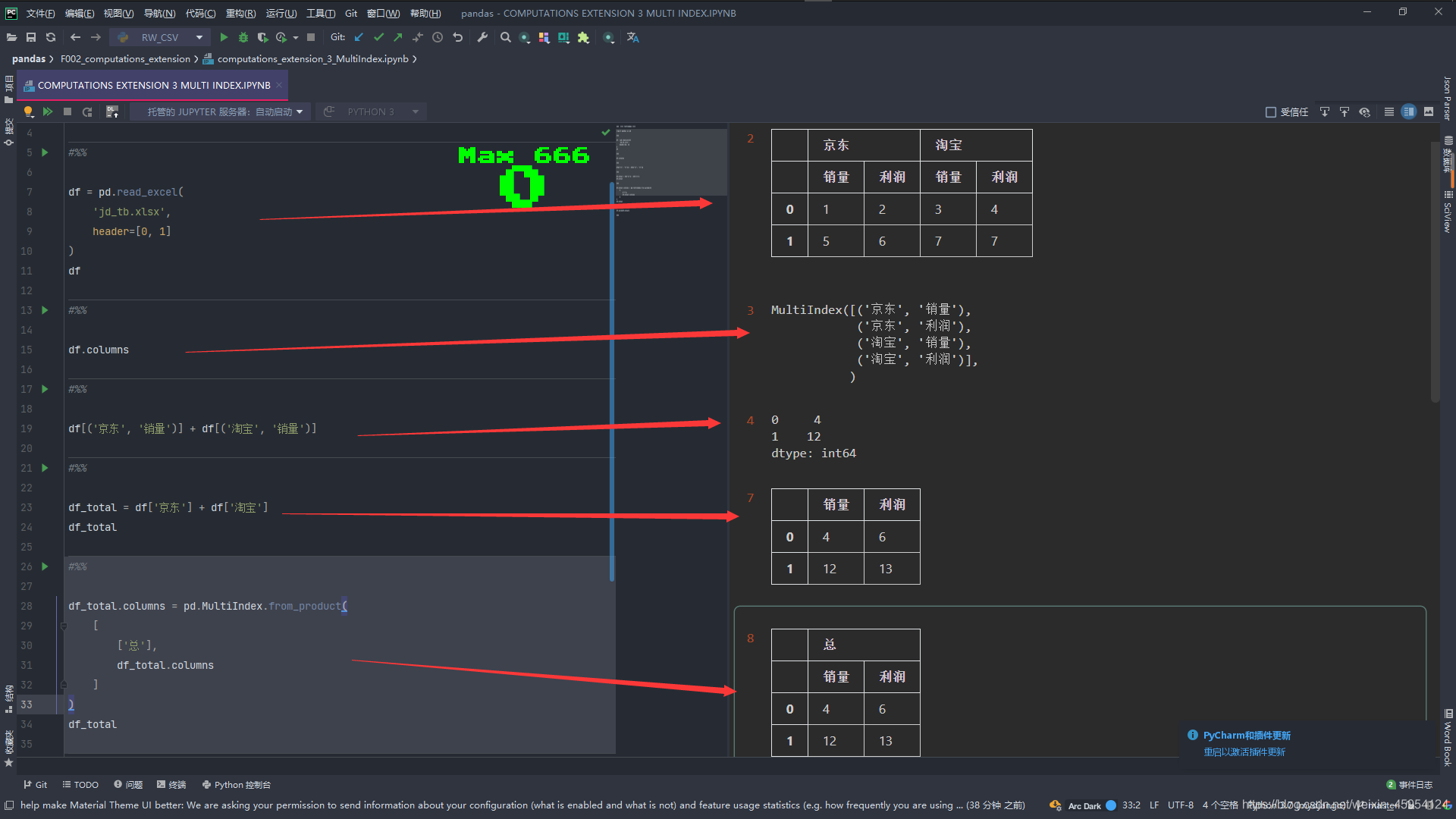

String-Dtype类型
convert_dtypes()将列转换为最有可能的类型
#%%
import pandas as pd
#%%
df = pd.DataFrame([
['a', 'b'],
['c', 1],
], columns=['X', 'Y'])
df
"""
X Y
0 a b
1 c 1
"""
#%%
# 查看数据类型 都是object类型
df.dtypes
#%%
# convert_dtypes() 将列转换为最有可能的类型
df = df.convert_dtypes()
df.dtypes
#%%
# 只选择string类型的列
df.select_dtypes(include='string')
#%%
# 默认object类型
pd.Series(['a', 'b'])
#%%
# 指定类型
# pd.Series(['a', 'b'], dtype='string')
# 如果有数字这样 转换类型
pd.Series(['a', 'b', None, 1]).astype('str').astype('string')
#%%
# 指定类型
pd.Series(['a', 'b'], dtype=pd.StringDtype())
#%%
# 转换类型
pd.Series(['a', 'b']).astype('string')
#%%
pandas查看数据的基本信息
DataFrame

#%%
import pandas as pd
#%%
df = pd.read_csv('tips.csv')
df
#%%
df.info()
#%%
df.describe()
#%%
df.values
#%%
df.to_numpy()
#%%
df.shape
#%%
df.columns.values.tolist()
#%%
df.index
#%%
df.head(3)
#%%
df.tail()
#%%
# pd.options.display.max_columns=3
# pd.options.display.max_rows=5
# df = pd.read_csv('tips.csv')
# df
#%%
df.memory_usage()
#%%
df
#%%
df.dtypes
Series




#%%
import pandas as pd
import numpy as np
#%%
s = pd.Series(
[1, 2, 3],
name='AAA'
)
s
#%%
s.describe()
#%%
s.name
#%%
s.dtype
#%%
s = pd.Series(
[1, 2, 3],
name='AAA'
)
#%%
s
#%%
s.unique()
#%%
s.value_counts()
#%%
s.is_unique
#%%
s = pd.Series(
['a', 'b', 'c'],
name='goods_id'
)
assert s.is_unique
#%%
s = pd.Series(
['a', 'b', '',
# None, pd.NA, pd.NaT
]
)
s
#%%
len(s)
#%%
s.count()
#%%
len(s) == s.count()
#%%
s.notna()
#%%
all(s.notna())
#%%
s1 = pd.Series([1,2,3])
s2 = pd.Series([1,2,np.NaN]).fillna(0)
s1 + s2
missing data 缺失值
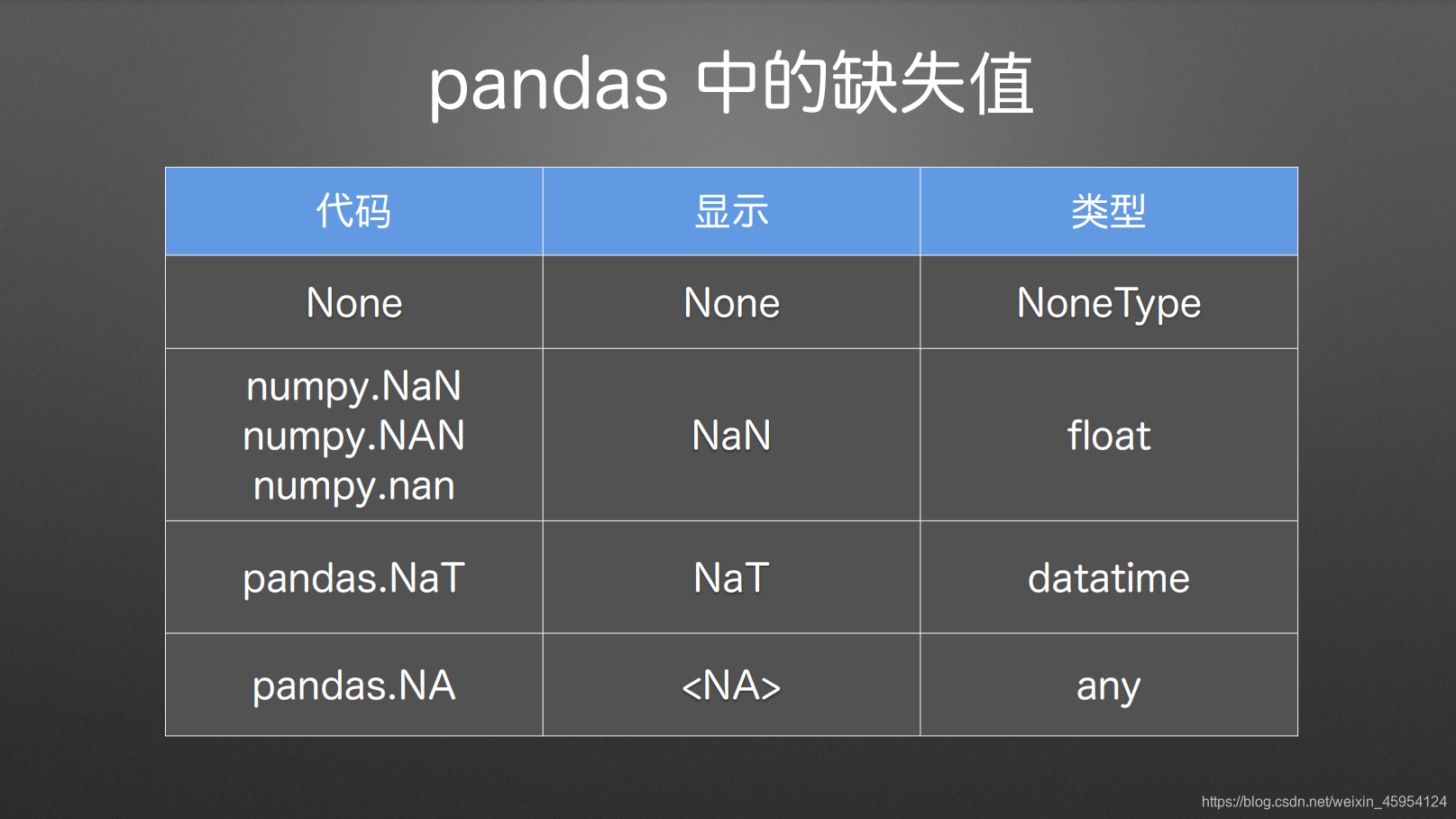
检测空值 isna()、notna()、isnull()、notnull()


取反
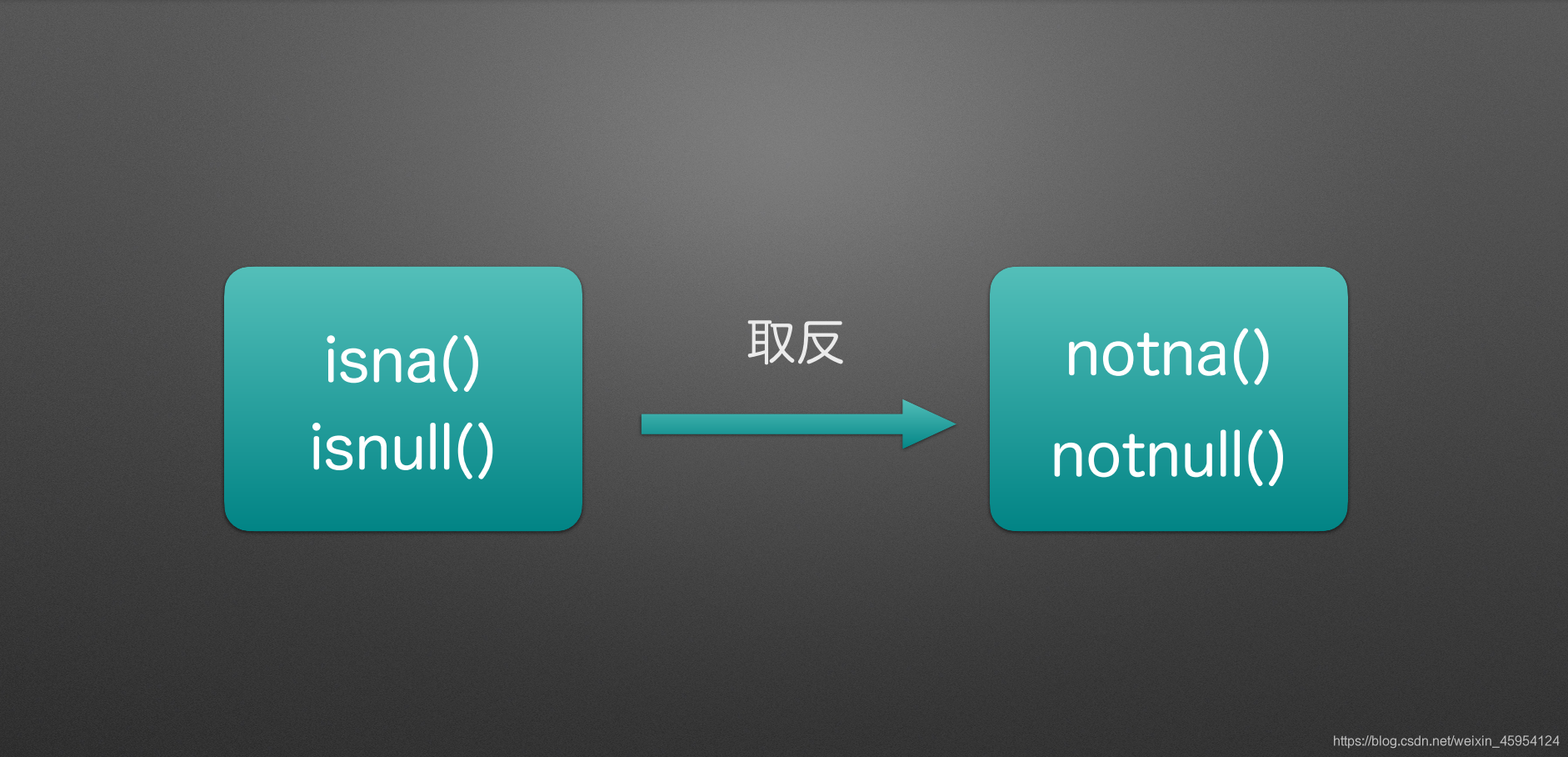
代码实例 用到方法
isna()
notna()
isnull()
notnull()
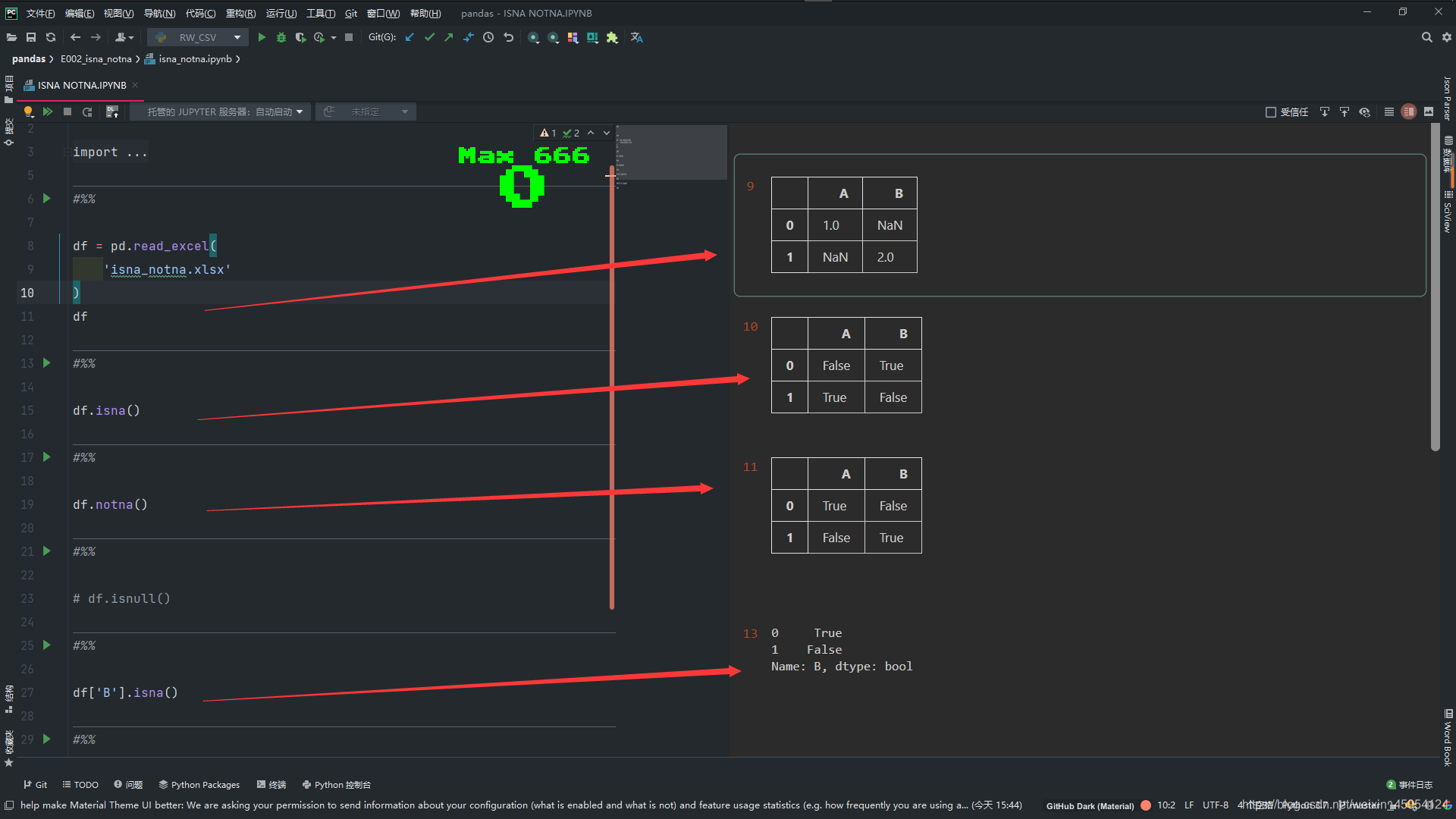
#%%
import pandas as pd
import numpy as np
#%%
df = pd.read_excel(
'isna_notna.xlsx'
)
df
#%%
df.isna()
#%%
df.notna()
#%%
# df.isnull()
#%%
df['B'].isna()
删除缺失值 dropna()

代码实例 用到方法
Series.dropna( self , inplace = True )
- inplace 代表是否原地修改 默认False不修改
DataFrame.dropna( self, axis = 0, how = ‘all’, subset = None, inplace = False )
- axis 指定行或列 0=行 1=列
- how
- all 只有那一行全部为空值才进行删除
- any 只要那一行有空值 无论单个还是多个 都删除
- subset 检测所有的列 可以传入一个列表 [‘A’,’C’] 只观察A C列 如果axis=1 那么观察 A C行
- inplace 代表是否原地修改 默认False不修改
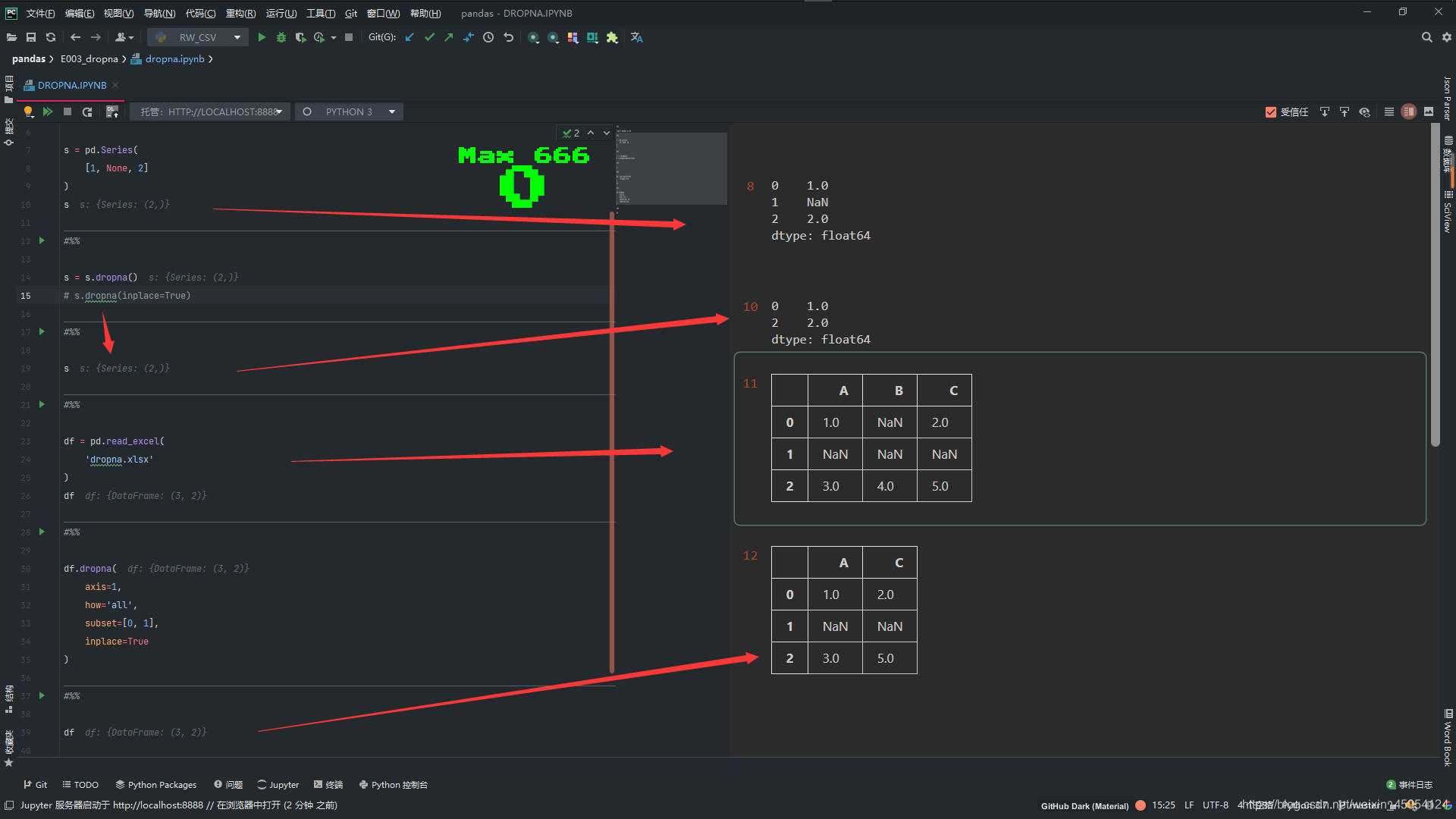
#%%
import pandas as pd
#%%
s = pd.Series(
[1, None, 2]
)
s
#%%
# 删除了下标为 1 的行 因为有空值
s = s.dropna()
# s.dropna(inplace=True)
#%%
# 这时没有被修改 如果inplace=True 那么就被修改了 或者向上边一样重新赋值
s
#%%
df = pd.read_excel(
'dropna.xlsx'
)
df
#%%
# df.dropna() 默认删除 有空值的 下标为 0 1的行
df.dropna(
axis=1,
how='all',
subset=[0, 1],
inplace=True
)
#%%
df
填充缺失值 fillna()
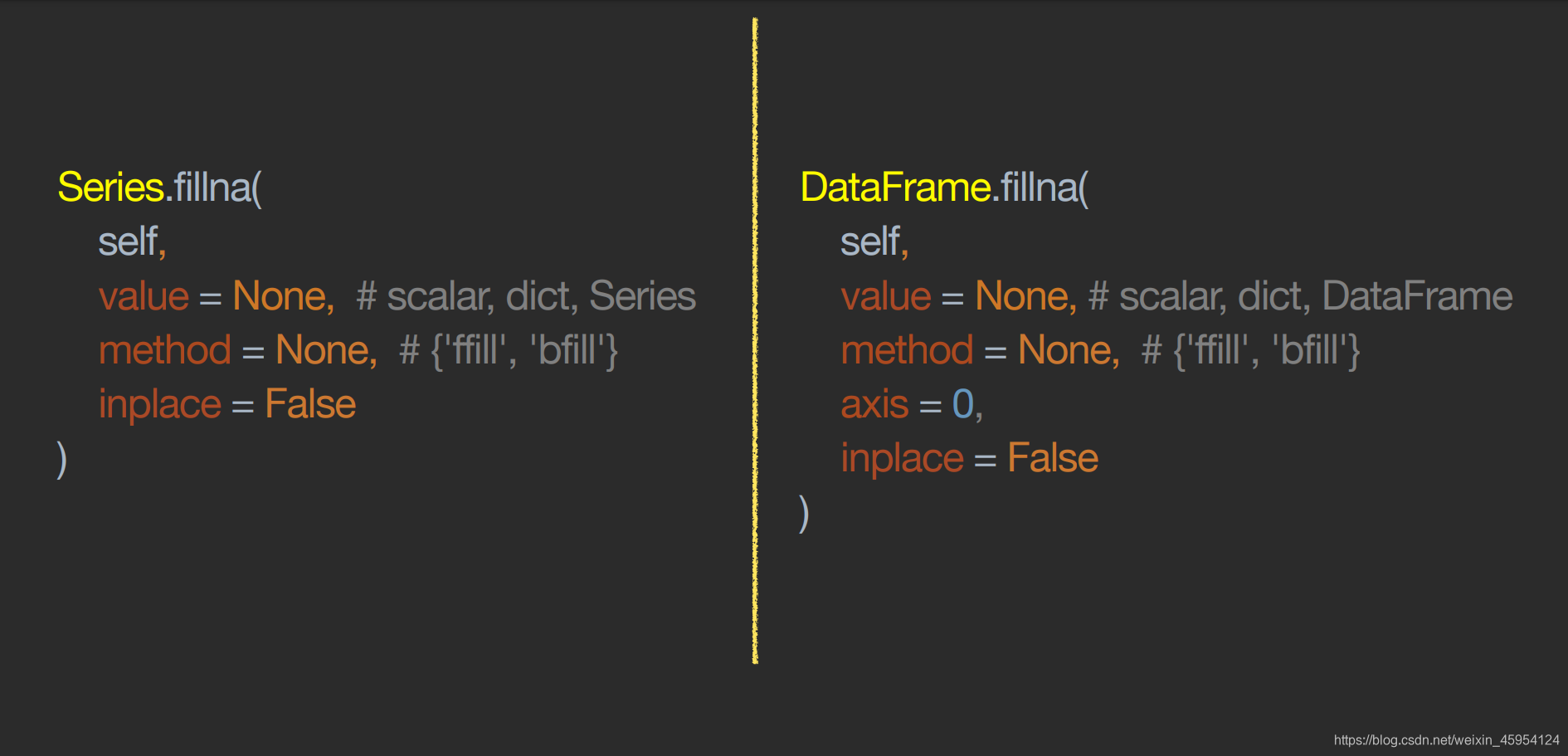

代码实例 用到方法
Series.fillna( self, value = None, method = None, inplace = False )
注意:value和method必须传一个 而且只能传一个
- value 可以传入标量、字典、Series
- method
- fill (forward向前的意思) 向前查找填充
- bfill (back向后的意思) 向后查找填充
- inplace 代表是否原地修改 默认False不修改
DataFrame.fillna( self, value = None, method = None, axis = 0 , inplace = False )
- value 可以传入标量、字典、DataFrame
- method
- fill (forward向前的意思) 向前查找填充
- bfill (back向后的意思) 向后查找填充
- axis = 0的话会垂直查找 =1的话就横向查找
- inplace 代表是否原地修改 默认False不修改
#%%
import pandas as pd
#%%
s = pd.Series(
[1, None, None, 2]
)
s
#%%
# 空值补充为0
# s.fillna(0)
#%%
# 字典格式填充
# s.fillna({0: 100, 1: 200})
#%%
s1 = pd.Series(
{0: 100, 1: 200, 2: 300})
s1
#%%
# 传入Series
s.fillna(s1)
#%%
# 指定以前填充
s.fillna(method='ffill')
#%%
# 指定以后填充
s.fillna(method='bfill')
#%%
df1 = pd.read_excel(
'fillna.xlsx'
)
df1
#%%
df2 = pd.read_excel(
'fillna.xlsx',
sheet_name=1
)
df2
#%%
# 空值补充0
df1.fillna(0)
#%%
# 传入字典
df1.fillna({
'B': 100,
'C': 200
})
#%%
# 传入DataFrame
df1.fillna(df2)
#%%
# 默认 垂直方向 向前查找
df1.fillna(method='ffill')
#%%
# 指定axis为1 水平方向查找 向后查找
df1.fillna(method='bfill',
axis=1)
#%%
填充缺失值 之 线性插值 interpolate()
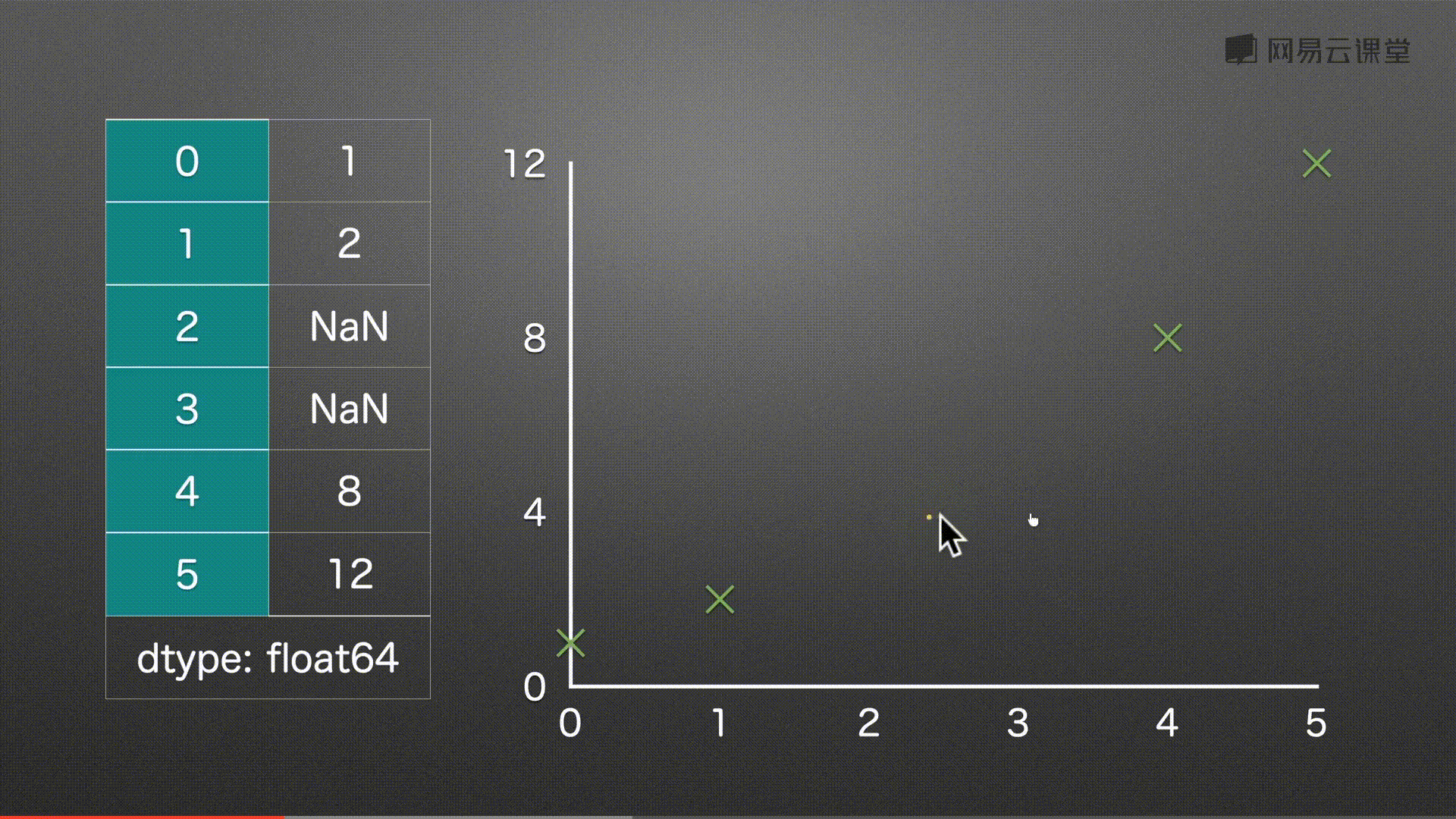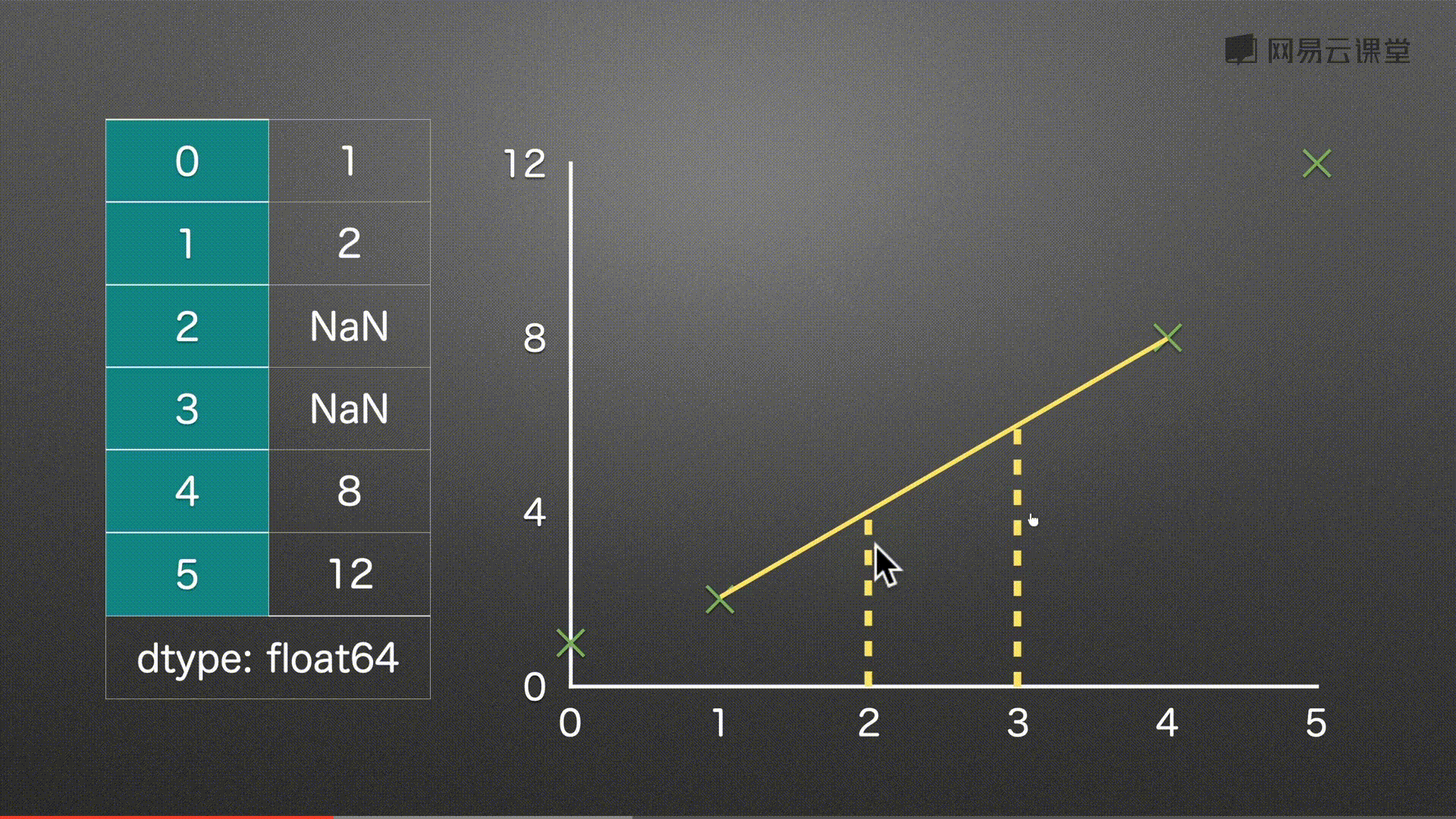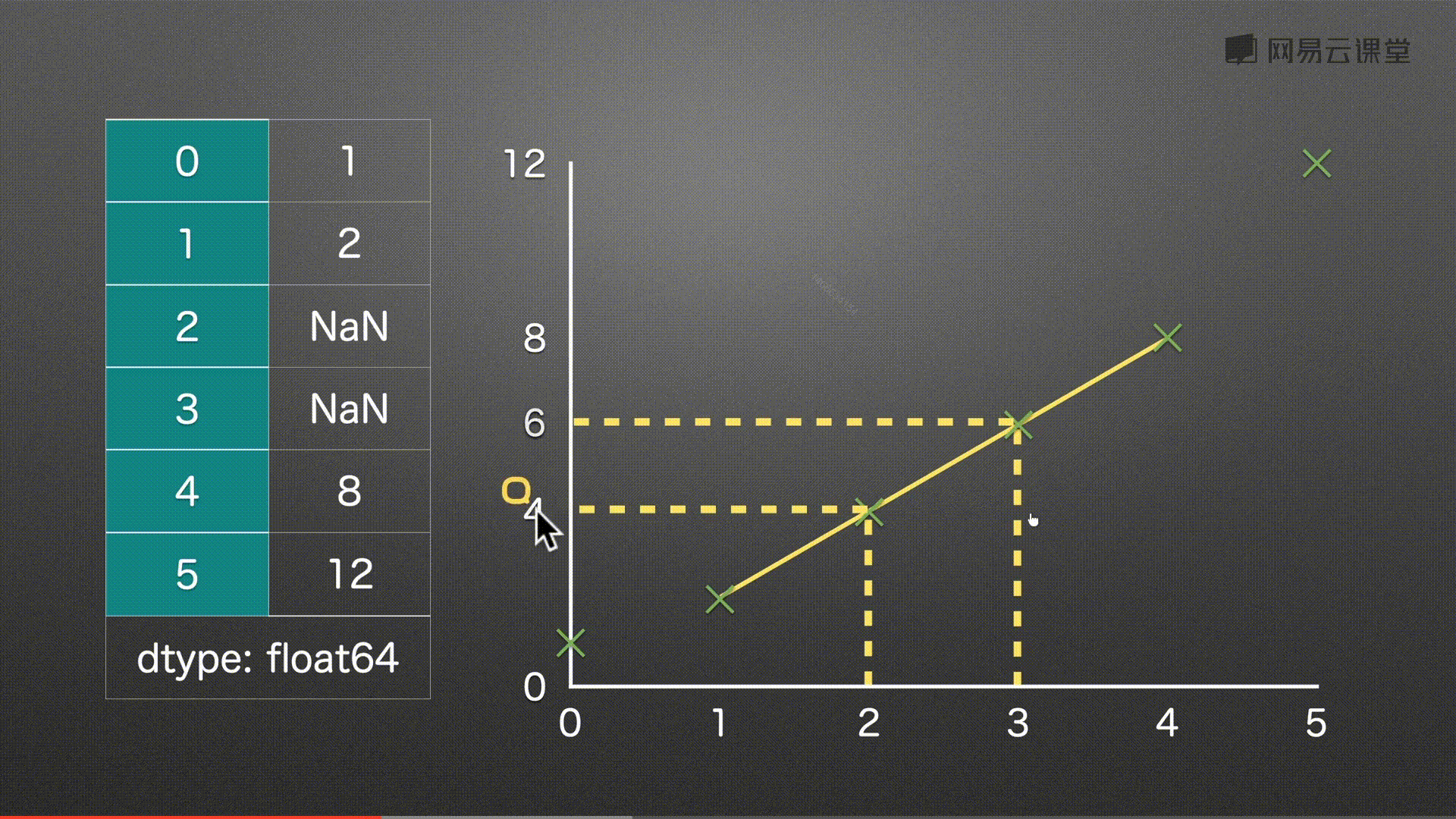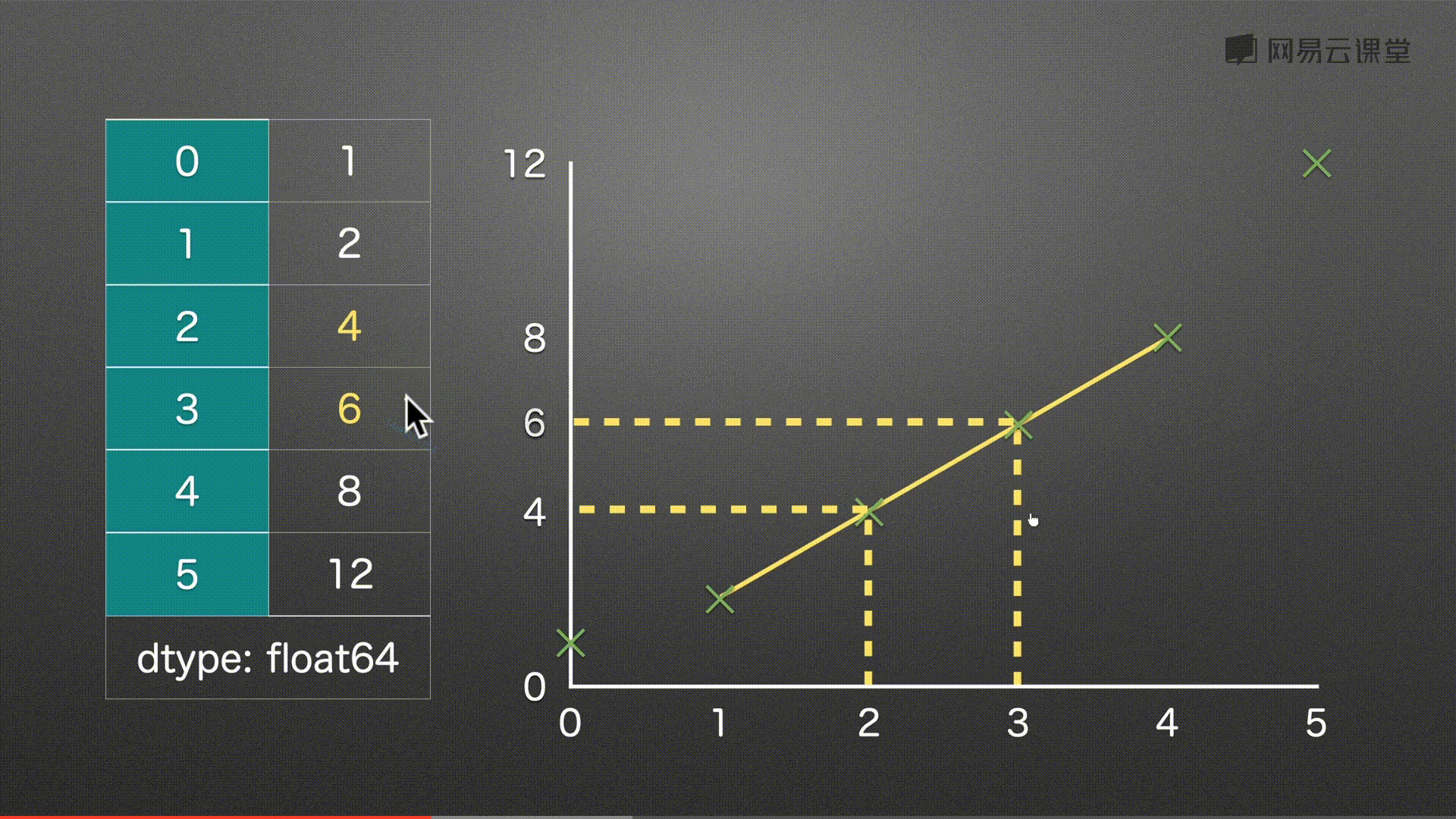
代码实例
#%%
import pandas as pd
#%%
s = pd.Series(
[1,2,None,None,5,
100, None, 200]
)
s
#%%
# 补充
s.interpolate()
#%%
df = pd.DataFrame([
[1,2,3,4],
[1,None,None,4],
[1,None,None,8],
[10,20,30,40],
])
df
#%%
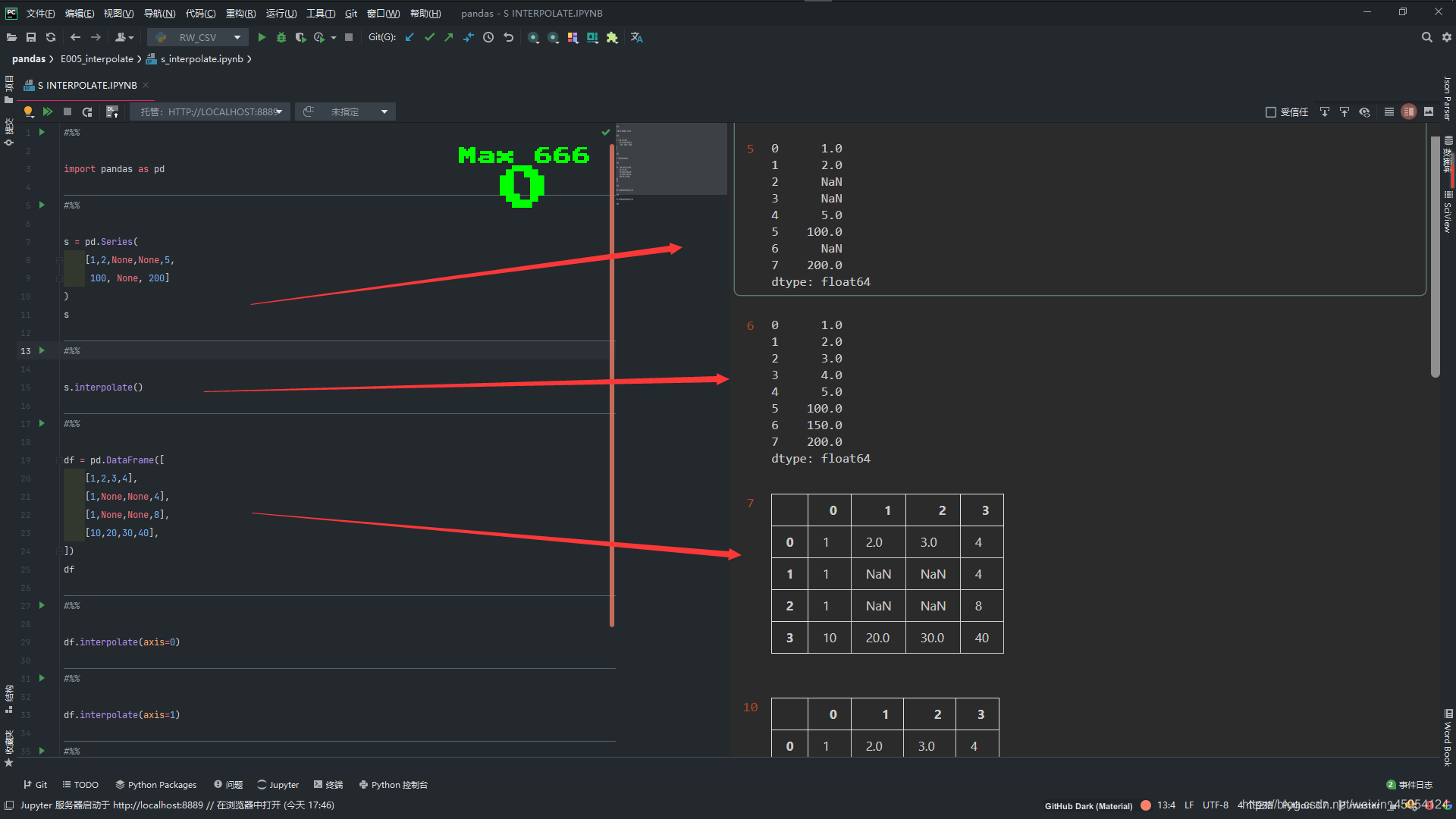
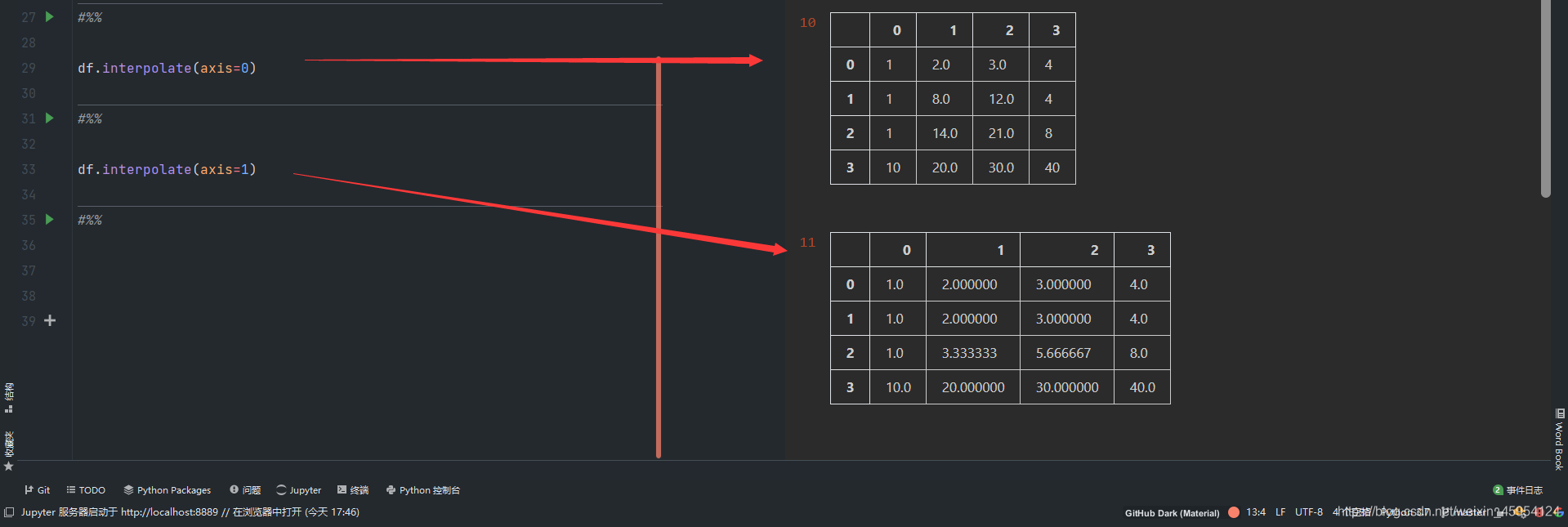
# 默认是0 纵向的
df.interpolate(axis=0)
#%%
# 横向的
df.interpolate(axis=1)
数据透视表 pivot() pivot_table()


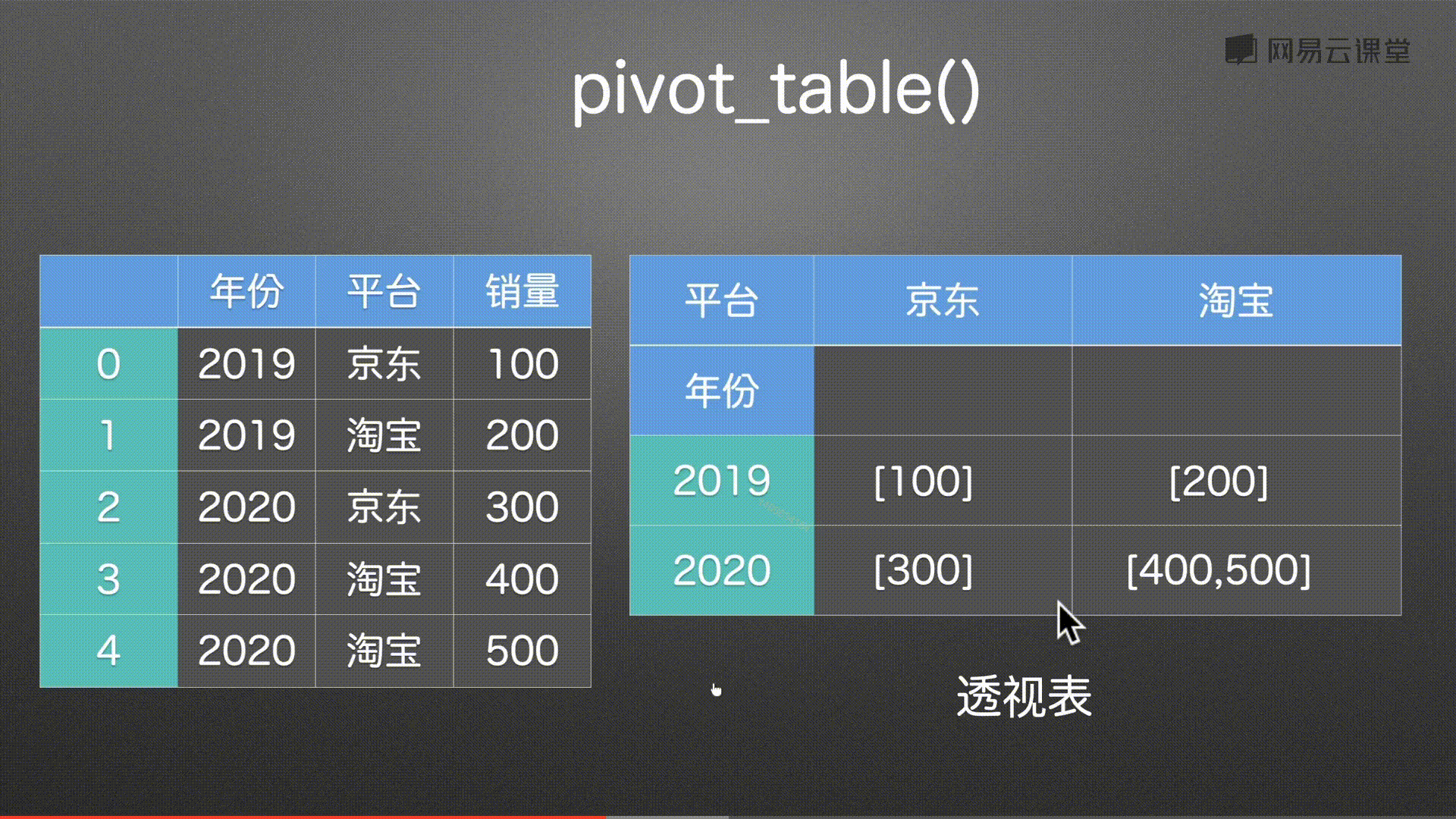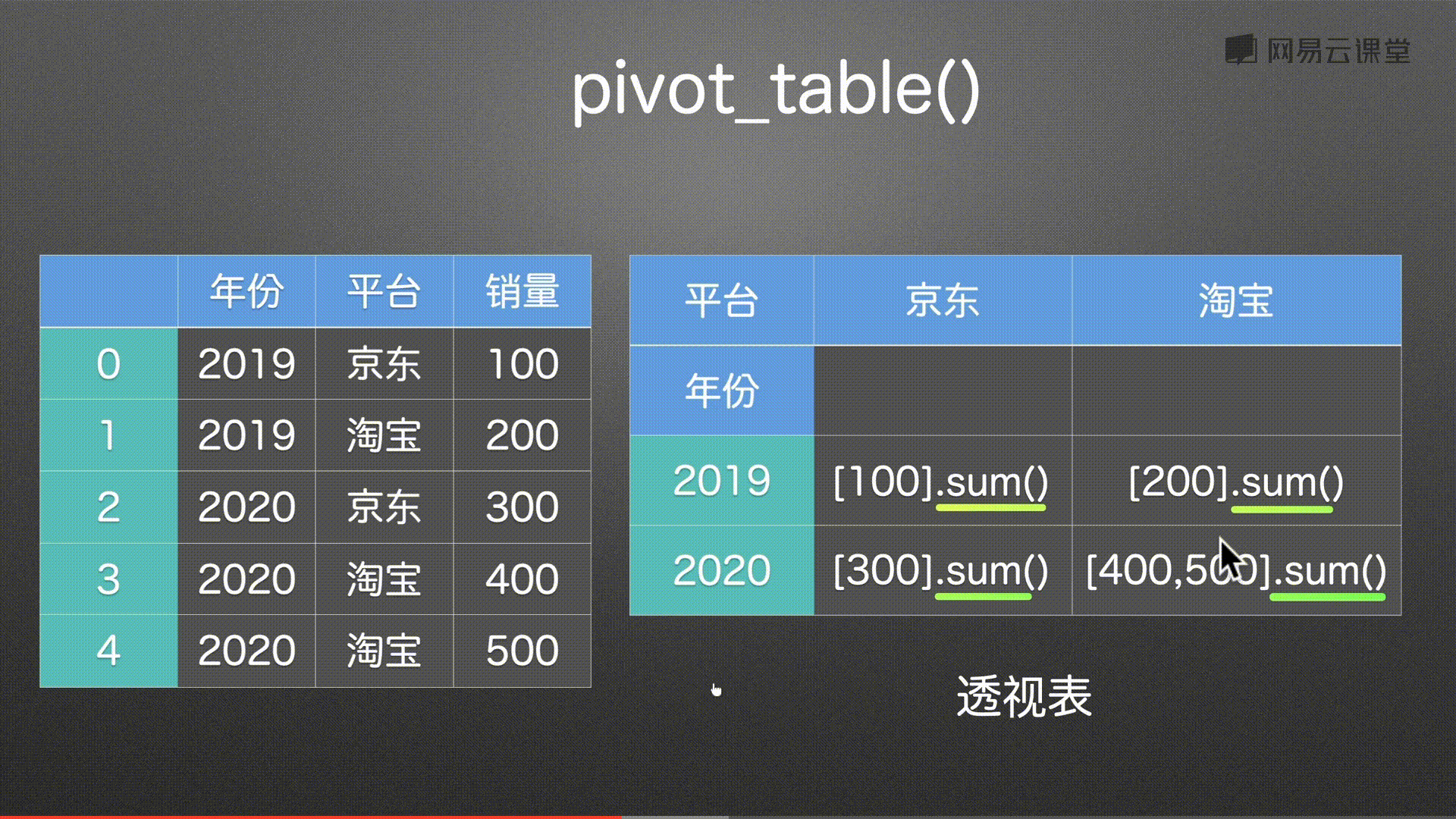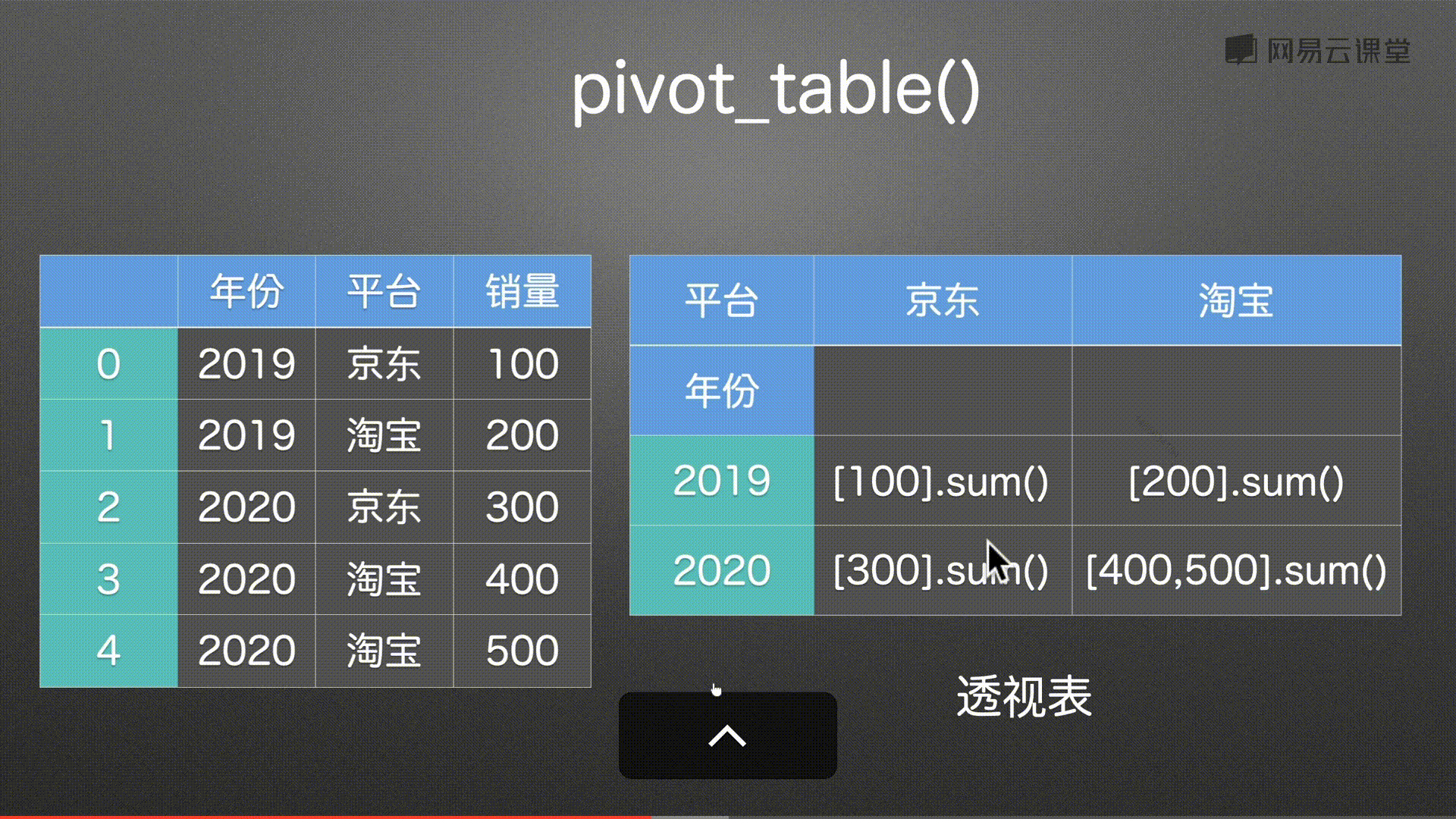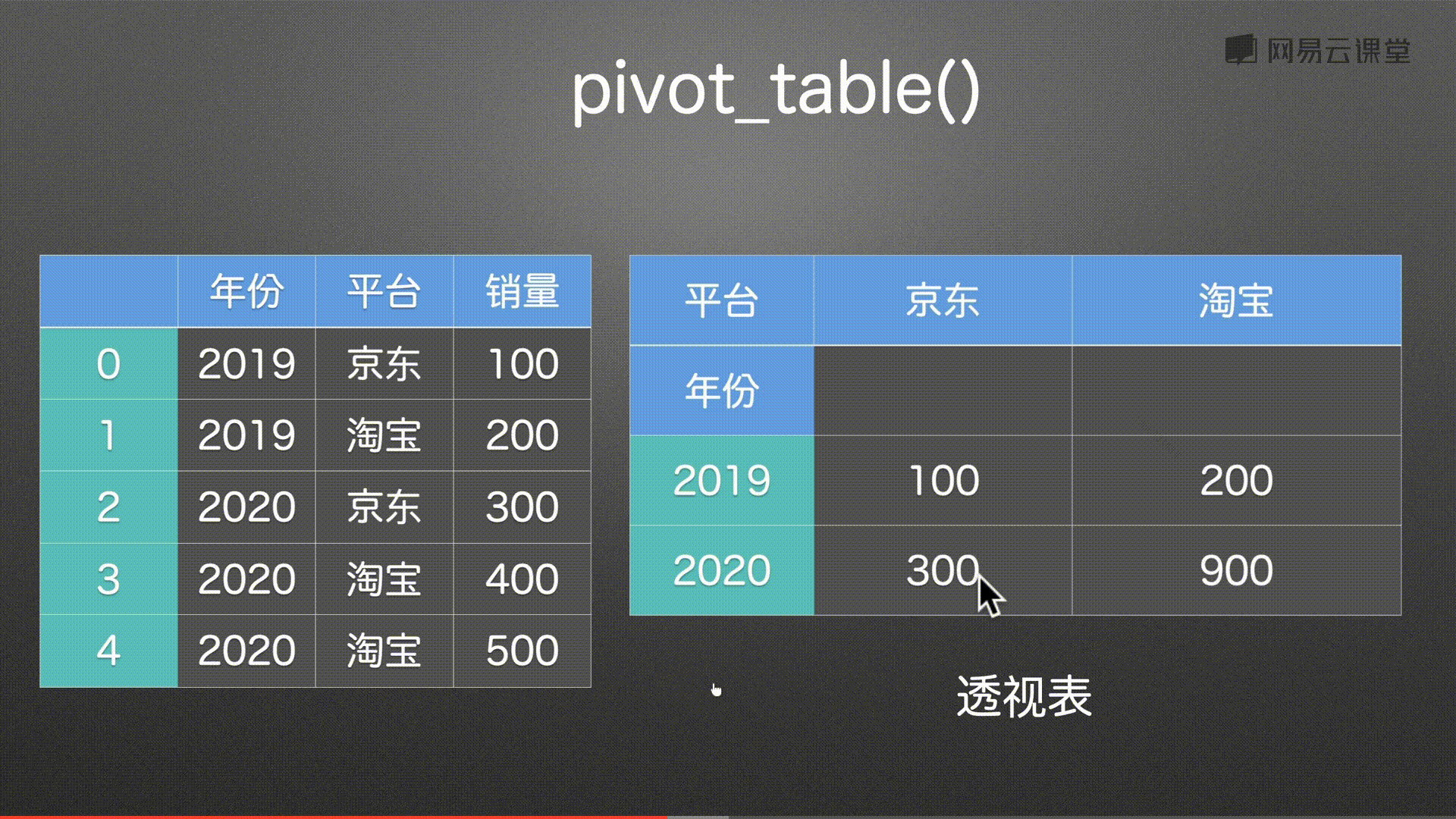
代码实例 用到方法
pd.pivot(df,index=’年份’,columns=’平台’,values=’销量’) 都可以传入列表
- index 指定列索引 唯一 就算重复也会只展示一个
- columns 指定行索引 唯一 就算重复也会只展示一个
- values 一般都是数值 int和float 不可索引重复
pd.pivot_table(df,index=’年份’,columns=’平台’,values=’销量’,aggfunc=’min’) 都可以传入列表
- index 指定列索引 唯一 就算重复也会只展示一个
- columns 指定行索引 唯一 就算重复也会只展示一个
- values 一般都是数值 int和float 索引可重复 是列表格式的
- aggfunc 可以进行聚合函数进行运算 求和 sum 求最大值传入字符串”max” 求平均值传入字符串 “mean” 求最小值传入字符串 “min”
- 还可以传入列表 根据不同的数据进行不同的计算
#%%
import pandas as pd
#%%
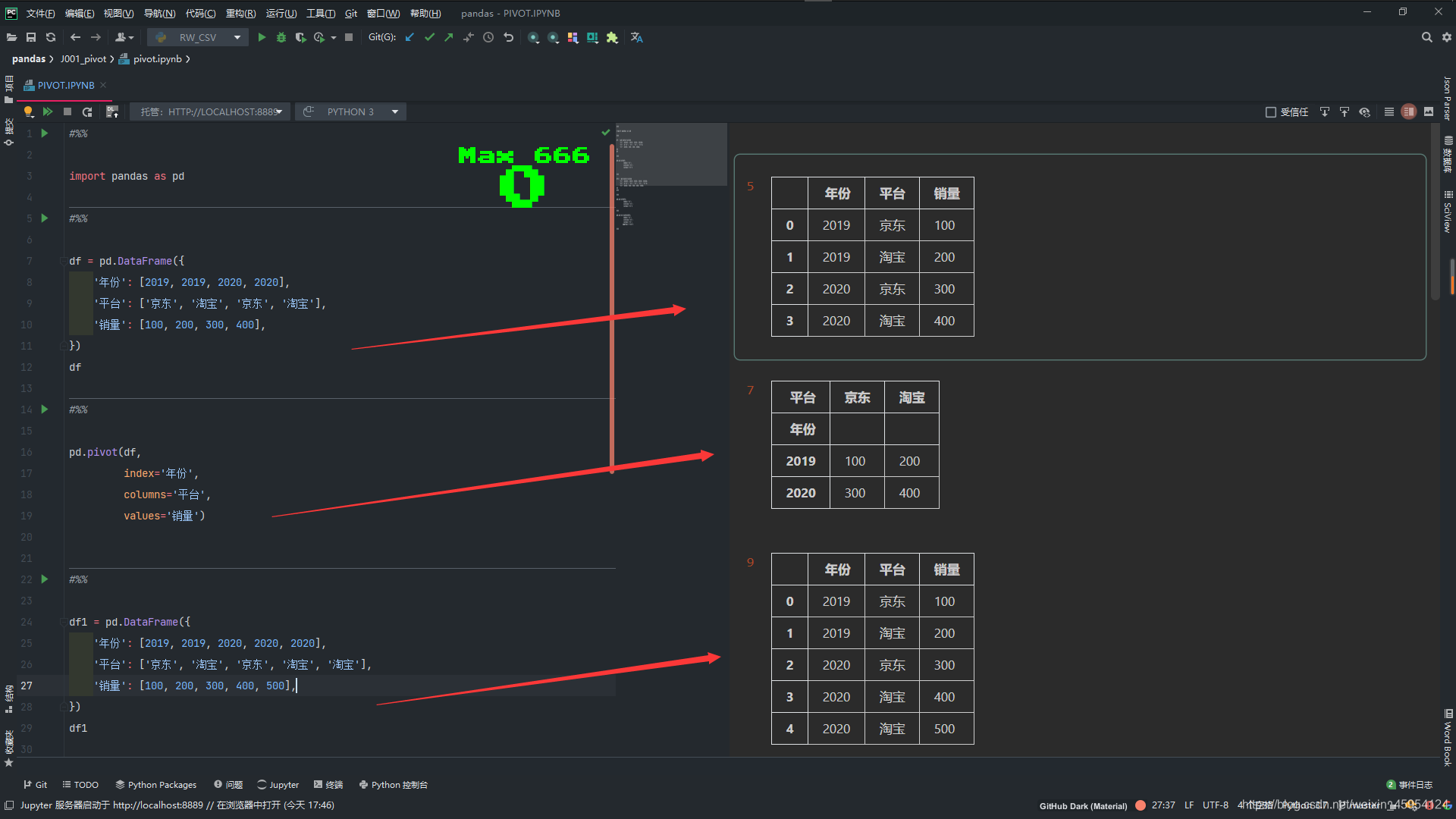
df = pd.DataFrame({
'年份': [2019, 2019, 2020, 2020],
'平台': ['京东', '淘宝', '京东', '淘宝'],
'销量': [100, 200, 300, 400],
})
df
#%%
pd.pivot(df,
index='年份',
columns='平台',
values='销量')
#%%
df1 = pd.DataFrame({
'年份': [2019, 2019, 2020, 2020, 2020],
'平台': ['京东', '淘宝', '京东', '淘宝', '淘宝'],
'销量': [100, 200, 300, 400, 500],
})
df1
#%%
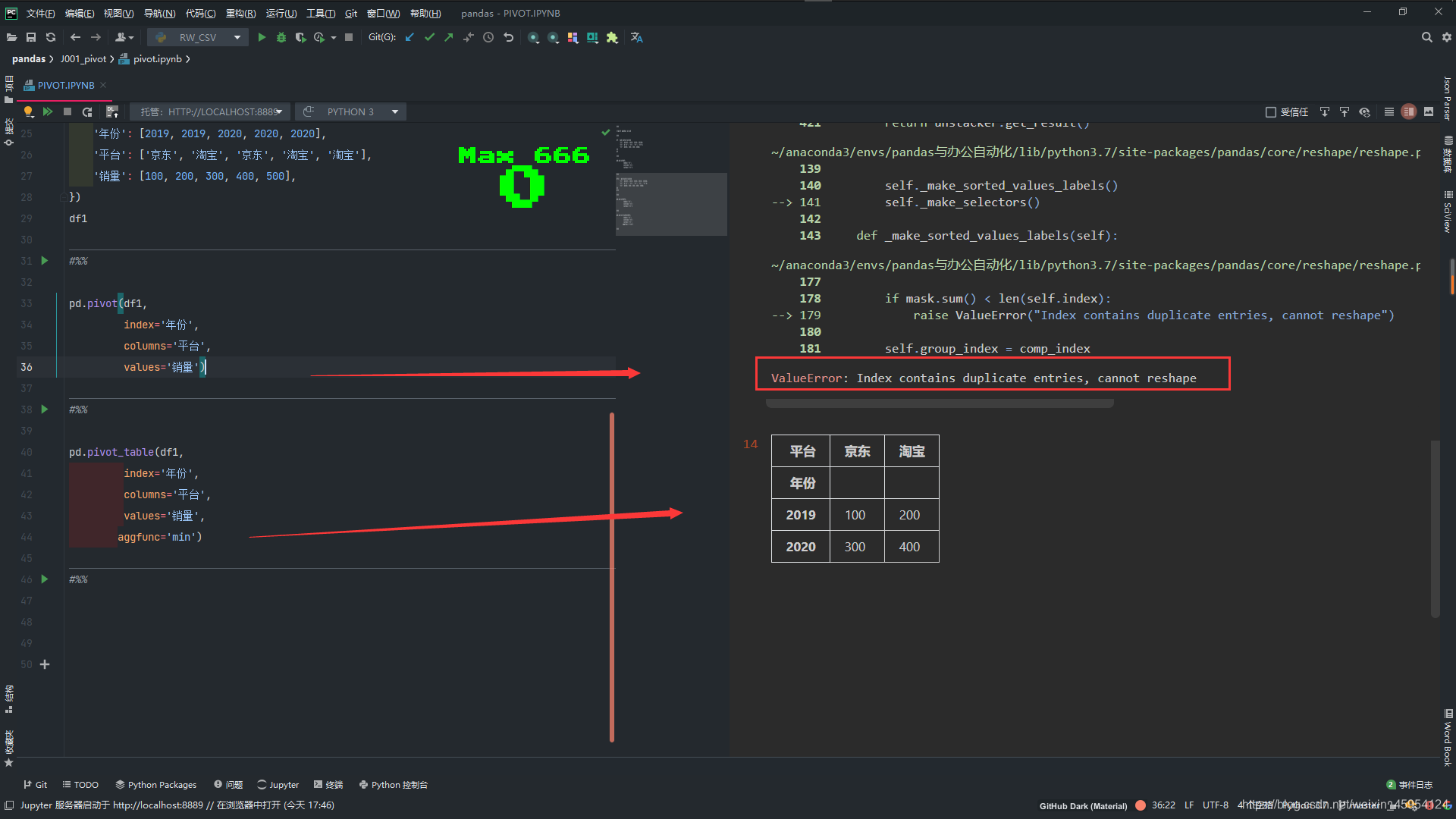
# 重复 不可索引
pd.pivot(df1,
index='年份',
columns='平台',
values='销量')
#%%
pd.pivot_table(df1,
index='年份',
columns='平台',
values='销量',
aggfunc='min')
#%%
pivot_table()详细用法
- aggfunc: aggregate function
- 聚合函数
- 求和: sum, ‘sum’, np.sum
- 求均值: ‘mean’, np.mean(默认)
- 最大值: max, ‘max’, np.max
- 最小值: min, ‘min’, np.min
- 数量: ‘count’
- 聚合函数
#%%
"""
aggfunc: aggregate function
聚合函数
求和: sum, 'sum', np.sum
求均值: 'mean', np.mean(默认)
最大值: max, 'max', np.max
最小值: min, 'min', np.min
数量: 'count'
"""
#%%
import pandas as pd
import numpy as np
#%%
df = pd.read_excel('2019销售总表.xlsx').convert_dtypes()
df
#%%
df.dtypes
#%%
# 默认查看平均值 aggfunc=sum是查看总销量
pd.pivot_table(
df,
index='货号',
values='销量',
aggfunc=sum
)
#%%
# 求总量和平均值
pd.pivot_table(
df,
index='货号',
values='销量',
aggfunc=[sum, 'mean']
)
#%%
pd.pivot_table(
df,
index='货号',
values=['销量', '实收金额'],
aggfunc=sum
)
#%%
# 销量的总数 实收金额的平均值
pd.pivot_table(
df,
index='货号',
values=['销量', '实收金额'],
aggfunc={
'销量': sum,
'实收金额': 'mean'
}
)
#%%
# 返回多层索引
pd.pivot_table(
df,
index=['货号', '尺码'],
columns='平台',
values='销量',
aggfunc=sum
)
#%%
# 根据日期的季度 df['日期'].dt.quarter 一年有四个季度 1234 每三个月为一个季度
pd.pivot_table(
df,
index=['货号', '尺码'],
columns=[
'平台',
df['日期'].dt.quarter],
values='销量',
aggfunc=sum
)
#%%
排序sort_index()&sort_values()
注意:中文为utf-8编码排序 图片错误

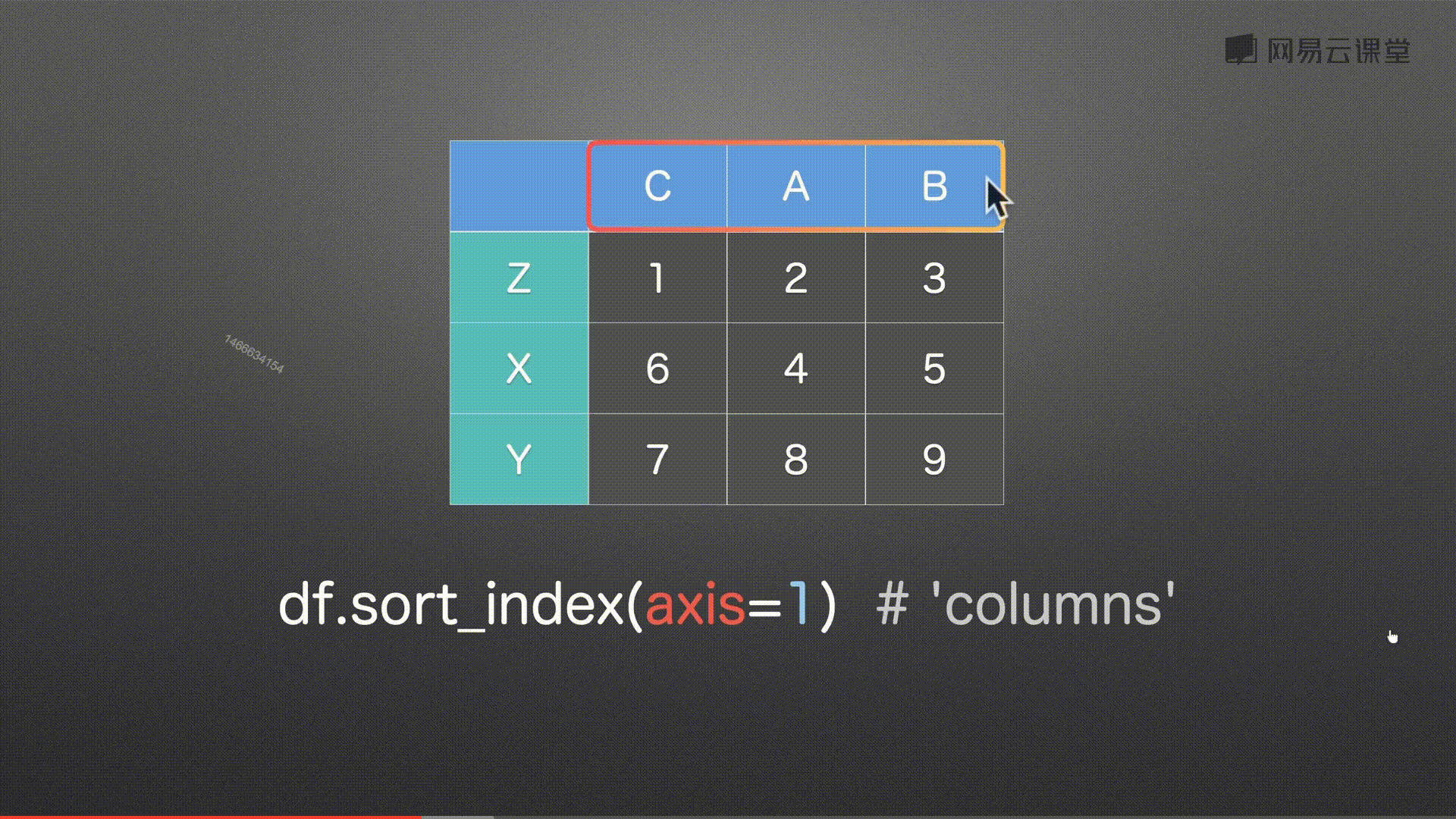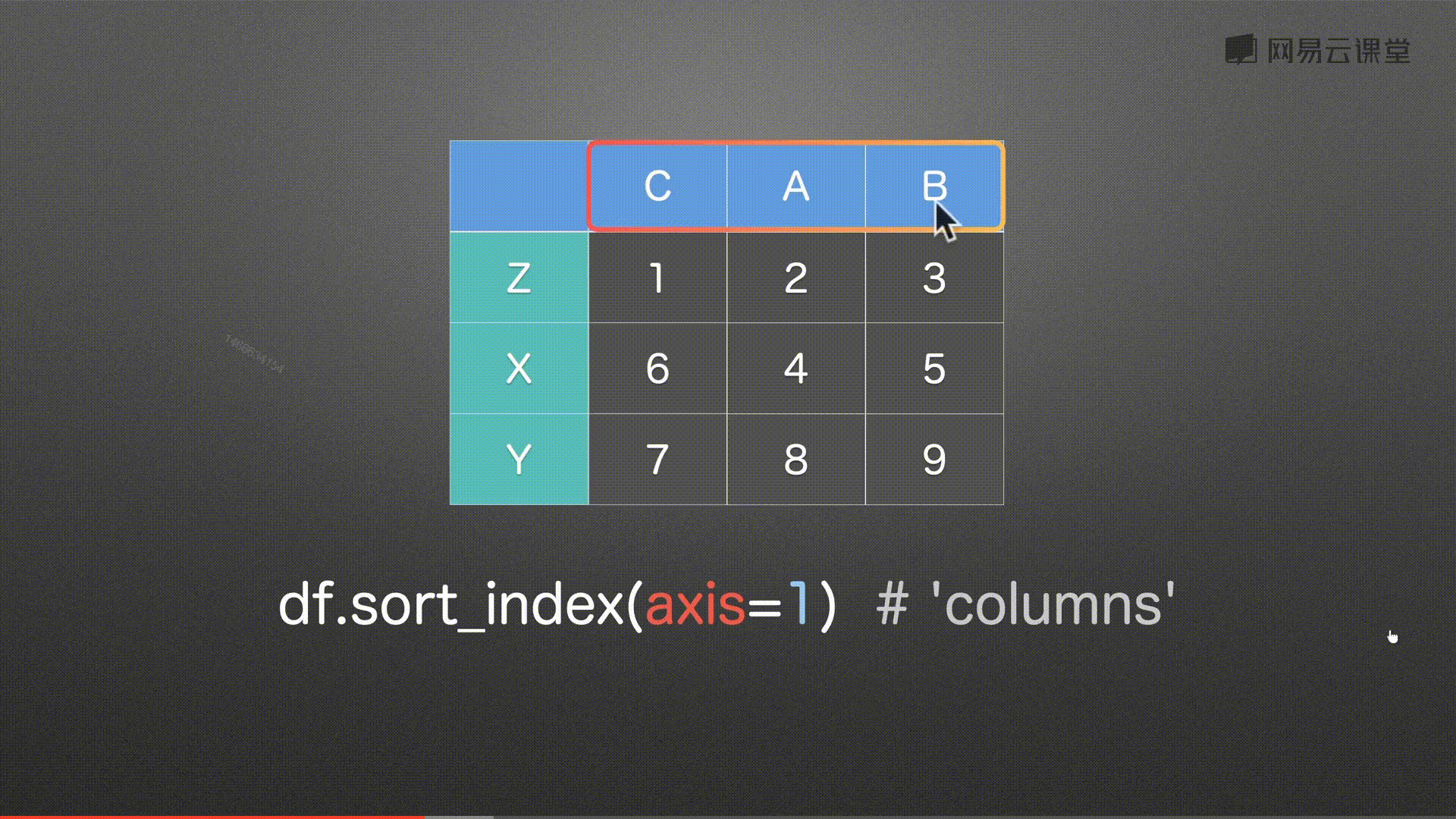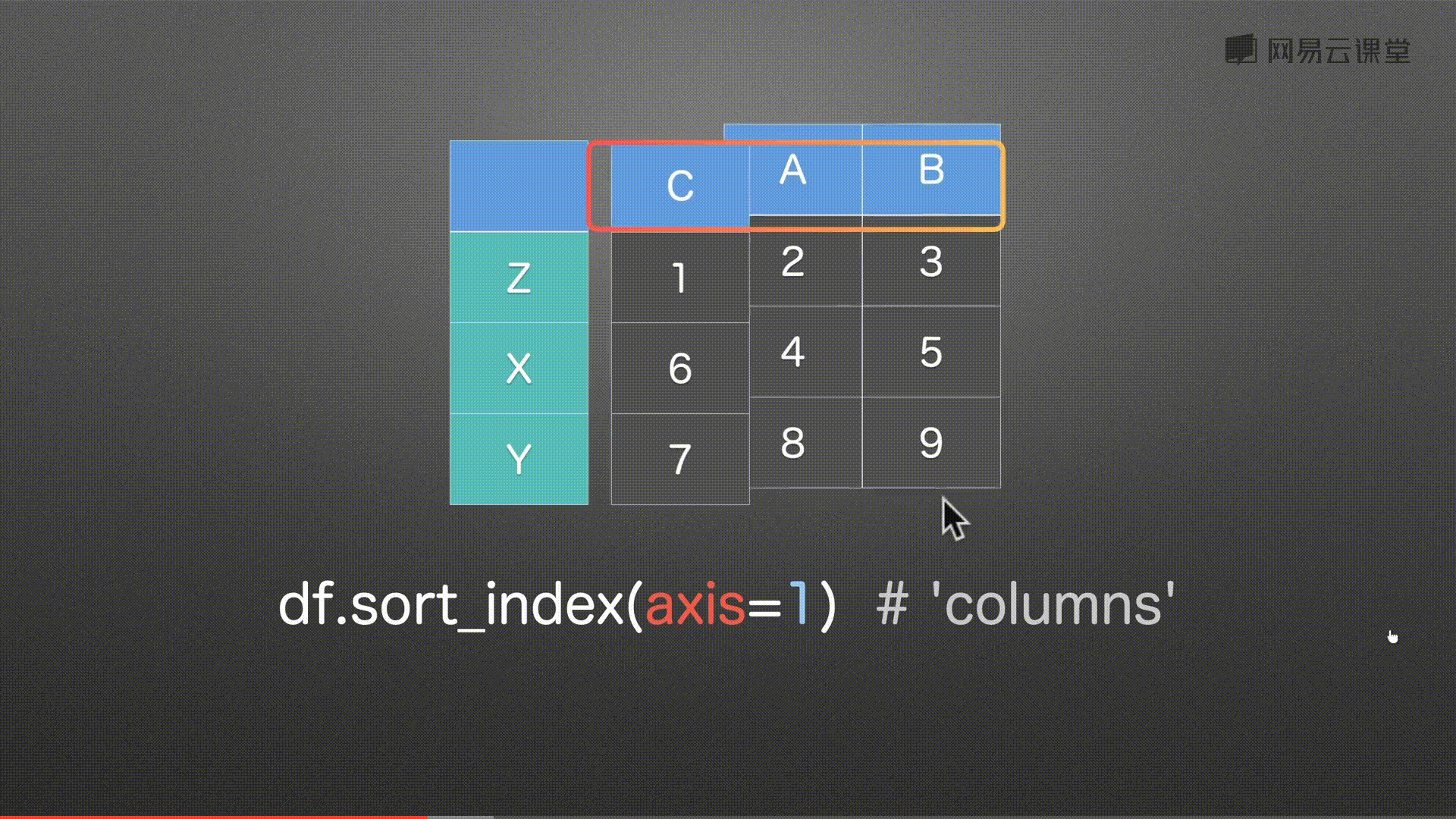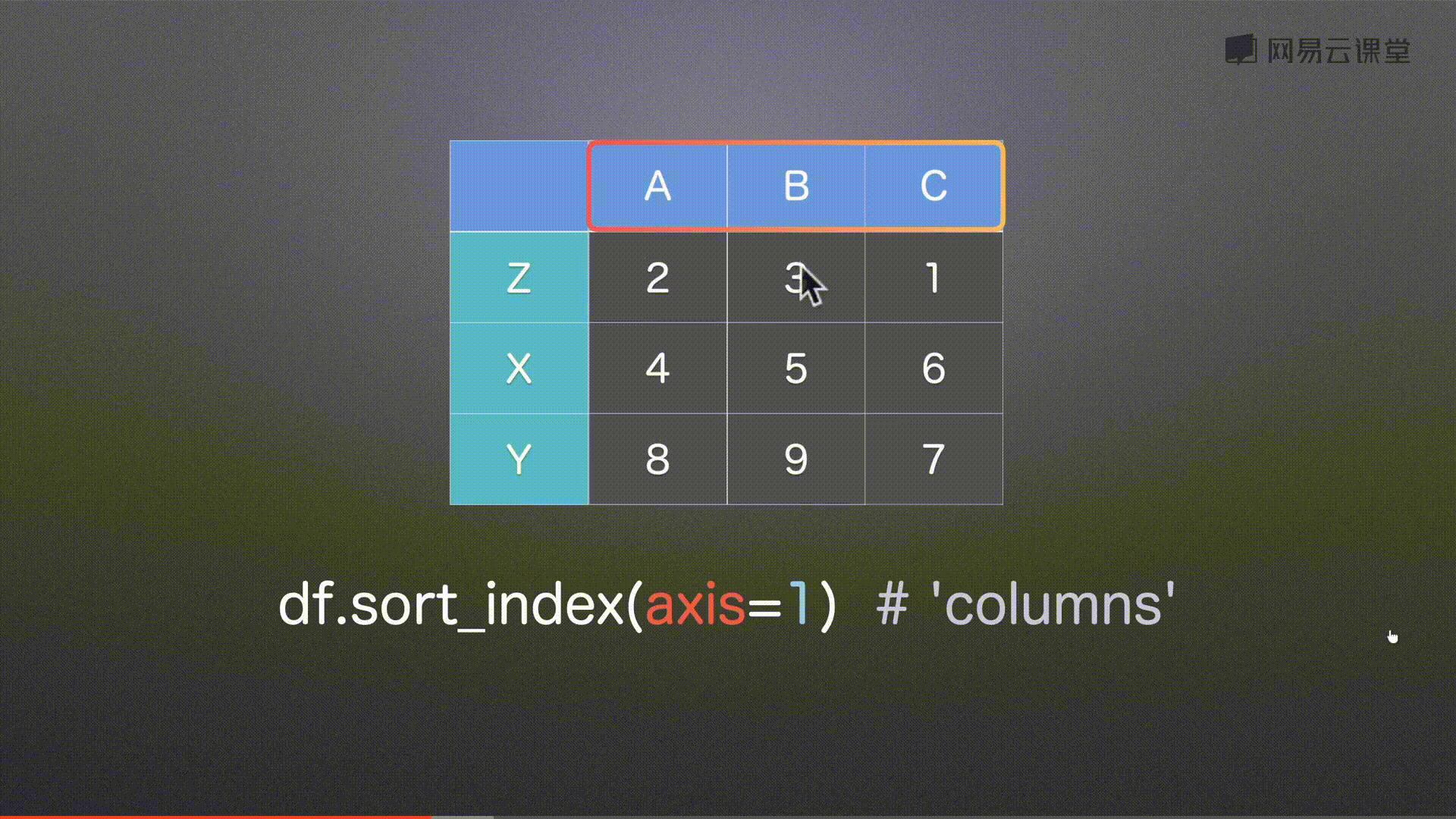


代码实例 用到方法
df.sort_index(ascending=False)
- ascending=False 降序 默认True升序
df.sort_values(‘索引’, ascending=False)
- ascending=False 降序 默认True升序
#%%
import pandas as pd
import numpy as np
#%%
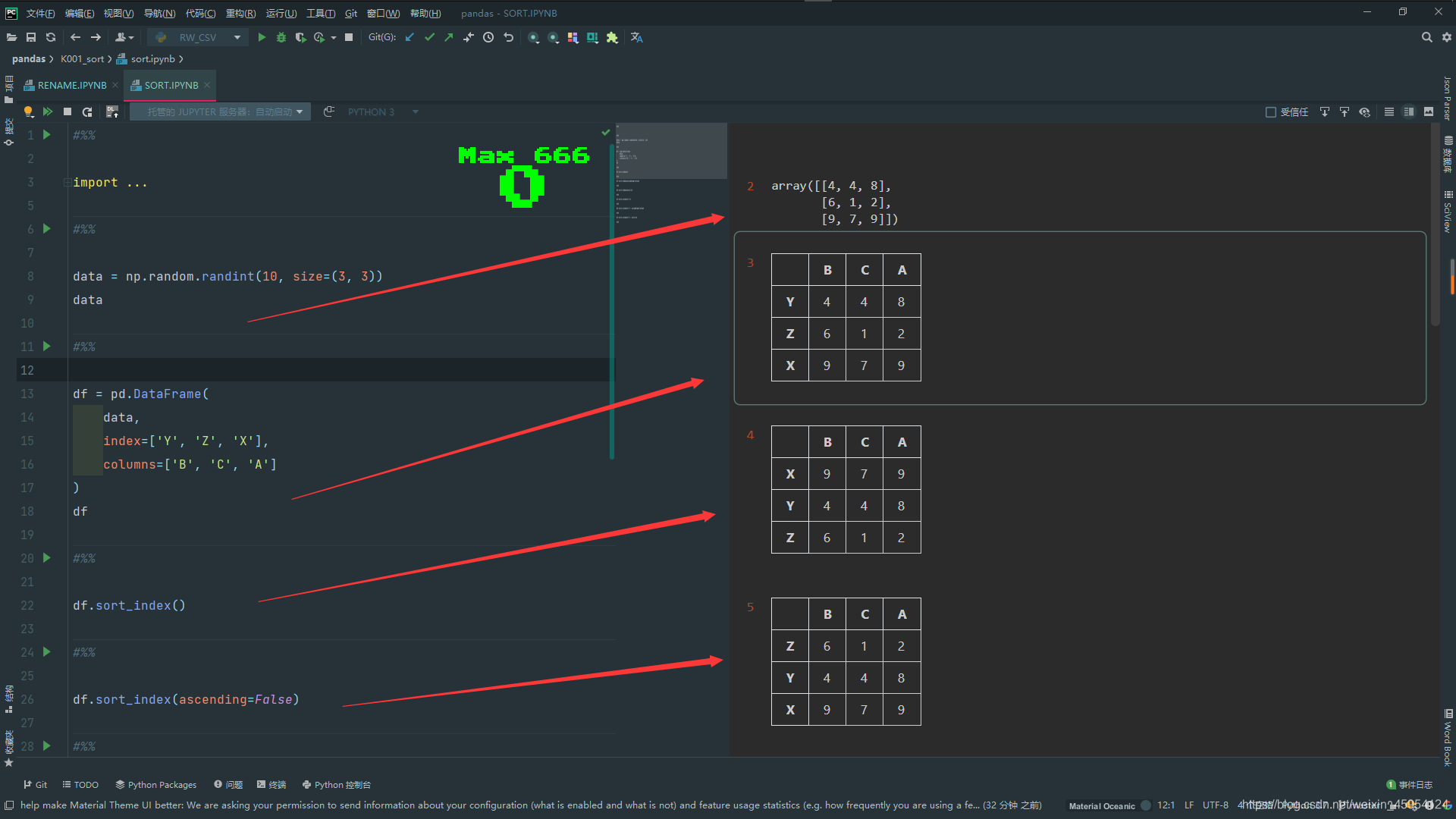
data = np.random.randint(10, size=(3, 3))
data
#%%
df = pd.DataFrame(
data,
index=['Y', 'Z', 'X'],
columns=['B', 'C', 'A']
)
df
#%%
# 默认axis=0 行索引
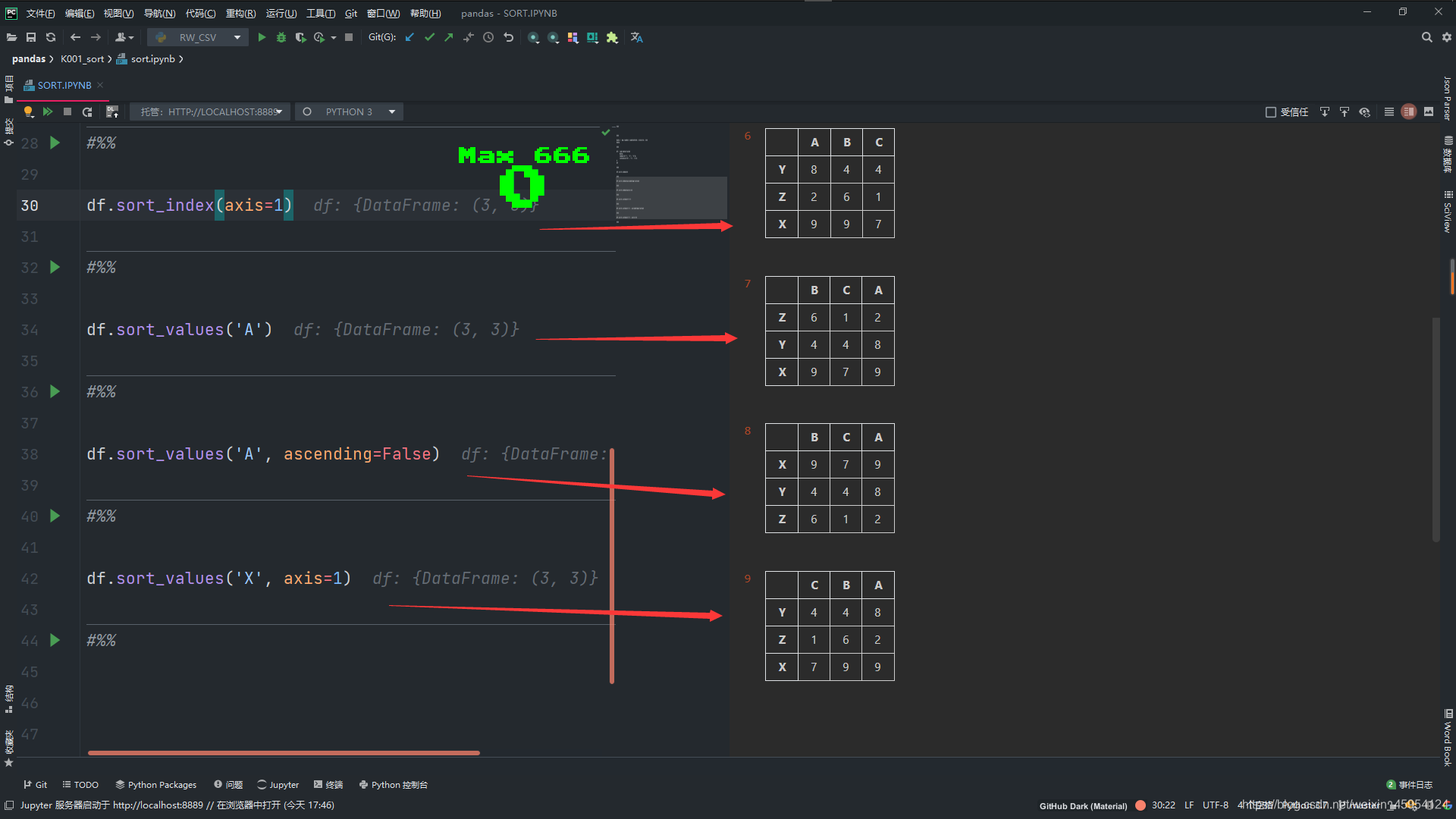
df.sort_index()
#%%
# ascending默认为True 为False时降序
df.sort_index(ascending=False)
#%%
# 根据列索引排序
df.sort_index(axis=1)
#%%
# 根据值排序
df.sort_values('A')
#%%
# 降序
df.sort_values('A', ascending=False)
#%%
# 对列进行排序
df.sort_values('X', axis=1)
扩展排序CategoricalDtype 减少内存 自定义排序

代码实例 用到方法
df[‘季节’].memory_usage() 查看使用的内存
tb.index.str.encode(‘utf-8’)查看中文的utf-8编码 16进制的 看看怎么排序中文的
my_type = pd.CategoricalDtype(categories=[‘春季’, ‘夏季’, ‘秋季’, ‘冬季’, ‘四季’],ordered=True)
- categories=[] 自定义排序
- ordered=True 否则不生效
#%%
import pandas as pd
import numpy as np
#%%
df = pd.read_excel(
'2019销售总表.xlsx'
).convert_dtypes()
df
#%%
df.dtypes
#%%
# 查看占用内存 10万多
df['季节'].memory_usage()
#%%
# 计算每个季节销量的和
tb = pd.pivot_table(
df,
index='季节',
values='销量',
aggfunc=sum
)
tb
#%%
# 排序 发现然并卵
tb.sort_index()
#%%
# 查看中文排序utf-8 16进制
tb.index.str.encode('utf-8')
#%%
# 自定义排序类型
my_type = pd.CategoricalDtype(
categories=['春季', '夏季', '秋季', '冬季', '四季'],
ordered=True
)
my_type
#%%
# 修改季节的类型 为我么自定义的
df['季节'] = df['季节'].astype(my_type)
df.dtypes
#%%
# 查看占用内存 一万多
df['季节'].memory_usage()
#%%
tb1 = pd.pivot_table(
df,
index='季节',
values='销量',
aggfunc=sum
)
tb1
#%%
# CategoricalIndex(['春季', '夏季', '秋季', '冬季', '四季'], categories=['春季', '夏季', '秋季', '冬季', '四季'], ordered=True, name='季# 节', dtype='category')
tb1.index
百分比变化 pct_change()
Series/DataFrame/GroupBy
pct_change() (Percentage change) 百分比变化
periods: 偏移量
freq: 频率(时间索引)
- “D”, “W”, “M”, “MS”, “B”
- DateOffset, Timedelta
limit: 最多连续填充空值个数
代码实例 用到方法
s.pct_change()
periods 偏移量
limit 最多连续填充空值个数
freq根据时间索引计算百分比 点击查看
date_range详情axis 默认axis=0上下 也就是列索引 axis=1时列索引 是左右
#%%
import pandas as pd
#%%
s = pd.Series([1,2,3,4])
s
#%%
# 今天/昨天-1 计算百分比
s.pct_change()
#%%
# 今天/前天-1 计算百分比
s.pct_change(periods=2)
#%%
s = pd.Series([1,2,None,None,3,4])
s
#%%
# 补充一次空值
s.pct_change(limit=1)
#%%
# 补充2次空值
s.pct_change(limit=2)
#%%
# 创建索引 20200101起始 20200131结束 freq='D' 天
index = pd.date_range(
'20200101',
'20200131',
freq='D'
)
index
#%%
df = pd.DataFrame({
'A': range(1, len(index)+1)
}, index=index)
df
#%%
# 相比较七天前的百分比
df['B'] = df['A'].pct_change(
freq='7D'
)
df
#%%
# B就是工作日的意思
df['B'] = df['A'].pct_change(
freq='B'
)
df
set_index()把已有列设置成index

代码实例 用到方法
df.set_index( ‘A’) 可以传入列表
drop 是否删除用作新索引的列 默认为True False的话就会保留
append 默认False 是否将新索引追加到原有的索引 True的话双层索引
inplace 默认False 是否将修改运用到原数据 使用的话就不需要重新赋值了
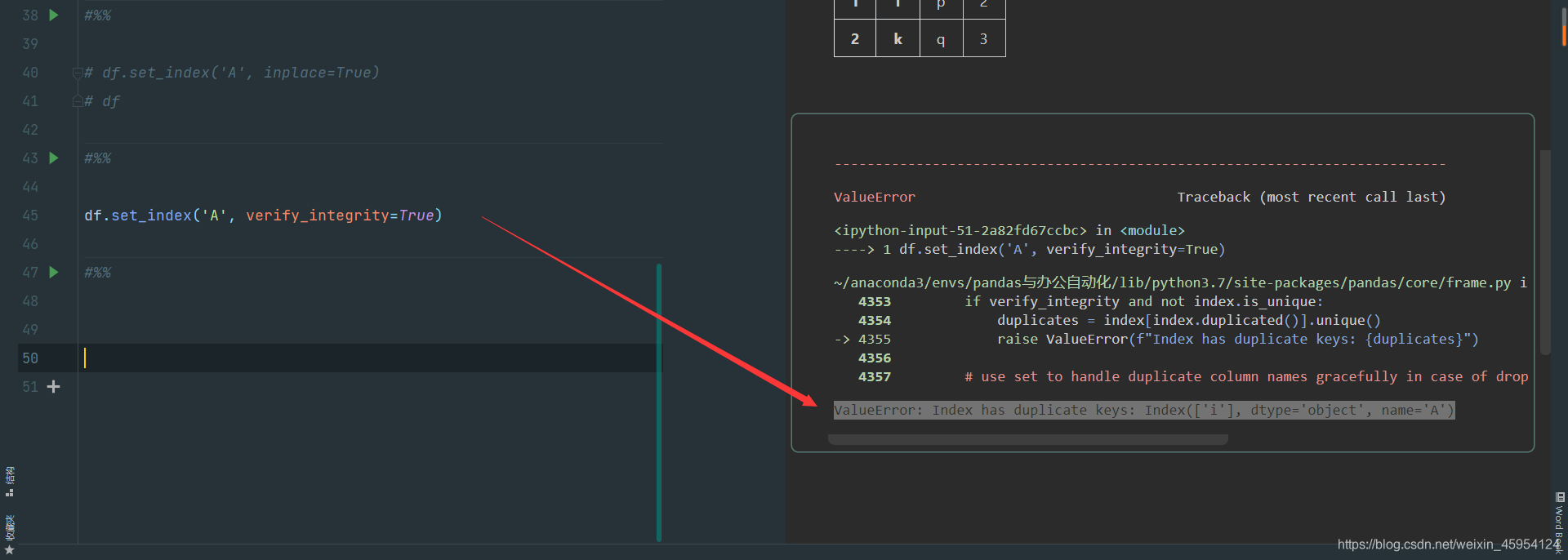
verify_integrity 检查新索引是否有重复 有重复会报错
ValueError: Index has duplicate keys: Index(['i'], dtype='object', name='A')
指定某一列或多列为新索引
#%%
import pandas as pd
#%%
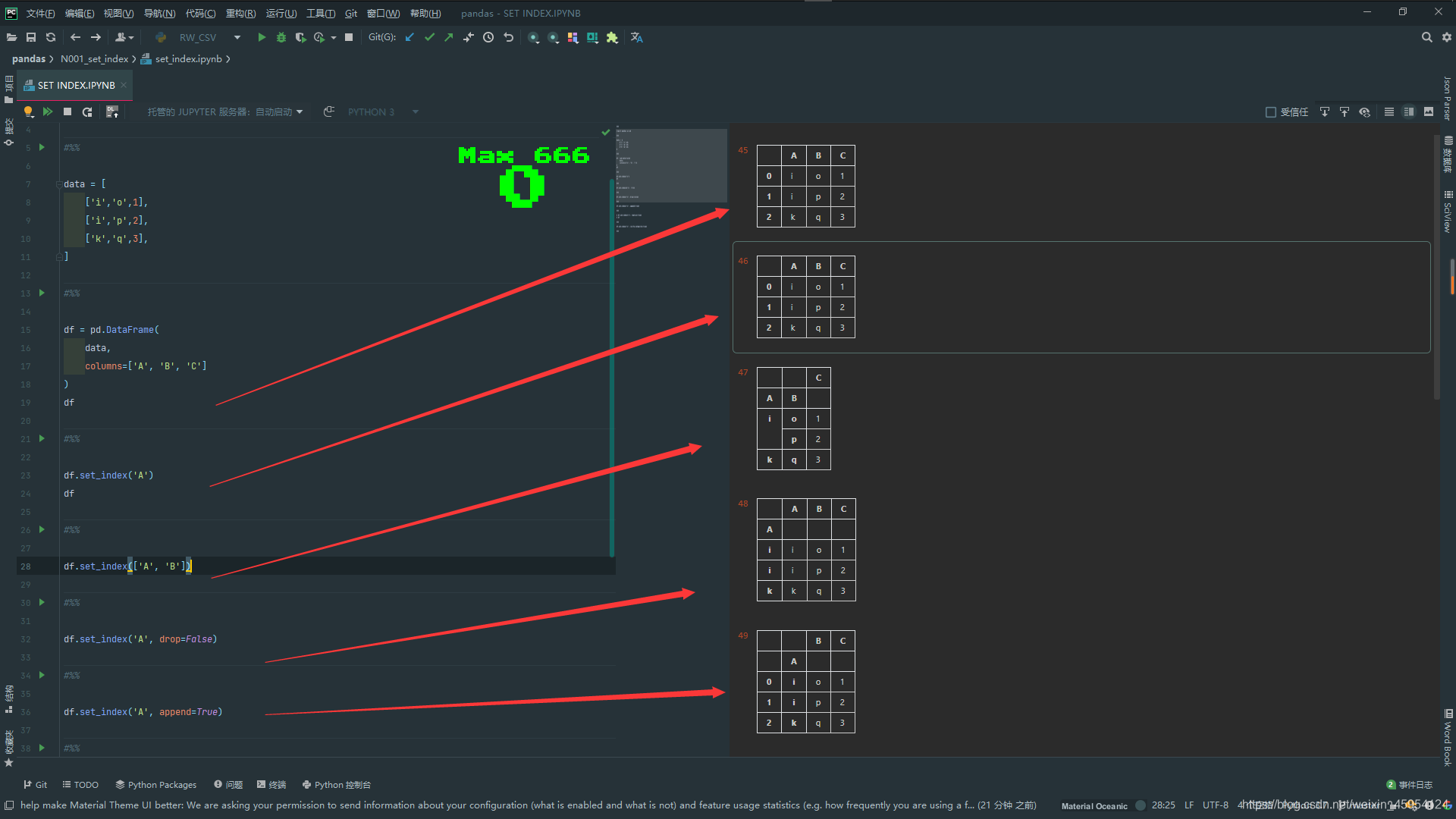
data = [
['i','o',1],
['i','p',2],
['k','q',3],
]
#%%
df = pd.DataFrame(
data,
columns=['A', 'B', 'C']
)
df
#%%
# 没有原地修改 返回修改后的
df.set_index('A')
df
#%%
# 传入列表
df.set_index(['A', 'B'])
#%%
# 不删除新索引的原数据
df.set_index('A', drop=False)
#%%
# 将新索引追加到原有的索引
df.set_index('A', append=True)
#%%
# df.set_index('A', inplace=True)
# df
#%%
# 检查新索引是否有重复
df.set_index('A', verify_integrity=True)
reset_index() 重置 index

代码实例 用到方法
df.reset_index()
- drop 是否丢弃原索引 默认False
- level 设置第几层为索引
- col_level
- col_fill
- inplace 默认False 是否将修改运用到原数据 使用的话就不需要重新赋值了
#%%
import pandas as pd
#%%
df = pd.DataFrame(
{'A': ['a','b','c']},
index=['x', 'y', 'z']
)
# df.index.name = 'B'
df
#%%
# 重置索引 name=index
df.reset_index()
#%%
# 重置索引 丢弃原数据
df.reset_index(drop=True)
#%%
# 创建多层索引数据
df = pd.DataFrame(
{'A': ['a','b','c']},
index=pd.MultiIndex.from_tuples(
[
('x', 1),
('y', 2),
('z', 3),
]
)
)
df
#%%
# 我们发现是俩层索引
df.reset_index()
#%%
#df.reset_index() 发现索引为 0 1 2 原来的索引为 level_1 level_2
# drop=True的话就会把俩层索引丢掉 为 0 1 2
df.reset_index(drop=True)
#%%
# 重置了第0层为新的列 索引为 123 name=level_0
df.reset_index(level=0)
#%%
# 重置了第1层为新的列 索引为 xyz name=level_0
df.reset_index(level=1)
#%%
df.reset_index(level=1, drop=True)
#%%
# 俩层列索引的df
df = pd.DataFrame(
{
('A', 'B'): ['a','b','c'],
('A', 'C'): ['d','e','f'],
},
index=['x', 'y', 'z']
)
df
#%%
# 行索引设置为第0层 name=index
df.reset_index(col_level=0)
#%%
# 行索引设置为第1层 name=index
df.reset_index(col_level=1)
#%%
# 第0层 index 第1层为空填充C
df.reset_index(col_level=0, col_fill='C')
#%%
# 第0层 index 第1层为空填充 index
df.reset_index(col_level=0, col_fill=None)
reindex() 使 Series/DataFrame 符合指定的索引


代码实例 使用方法
df.reindex([‘Z’, ‘Y’]) 默认行索引 如果没有补为空值NaN
- index 修改行索引
- columns 修改列索引
- axis =1 时为列索引 =0时行索引
#%%
import pandas as pd
#%%
df = pd.DataFrame(
[[1,2,3],
[4,5,6],
[7,8,9]],
columns=['A', 'B', 'C'],
index=['X', 'Y', 'Z']
)
df
#%%
# 默认行索引
df.reindex(['Z', 'Y'])
#%%
# 指定行索引
df.reindex(['Z', 'Y'], axis=0)
#%%
# 指定行索引
df.reindex(index=['Z', 'Y', 'O'])
#%%
# 指定列索引
df.reindex(['C', 'A', 'E'], axis=1)
#%%
# 指定列索引
df.reindex(columns=['C', 'A', 'E'])
#%%
# 取出为Series对象
df['A']
#%%
# 不需要指定值 直接指定就可以了
df['A'].reindex(['X', 'Z'])
reindex_like()符合指定索引
#%%
# reindex_like()
#%%
import pandas as pd
#%%
df1 = pd.DataFrame(
[[1,2,3],
[4,5,6],
[7,8,9]],
columns=['A', 'B', 'C'],
index=['X', 'Y', 'Z']
)
df1
#%%
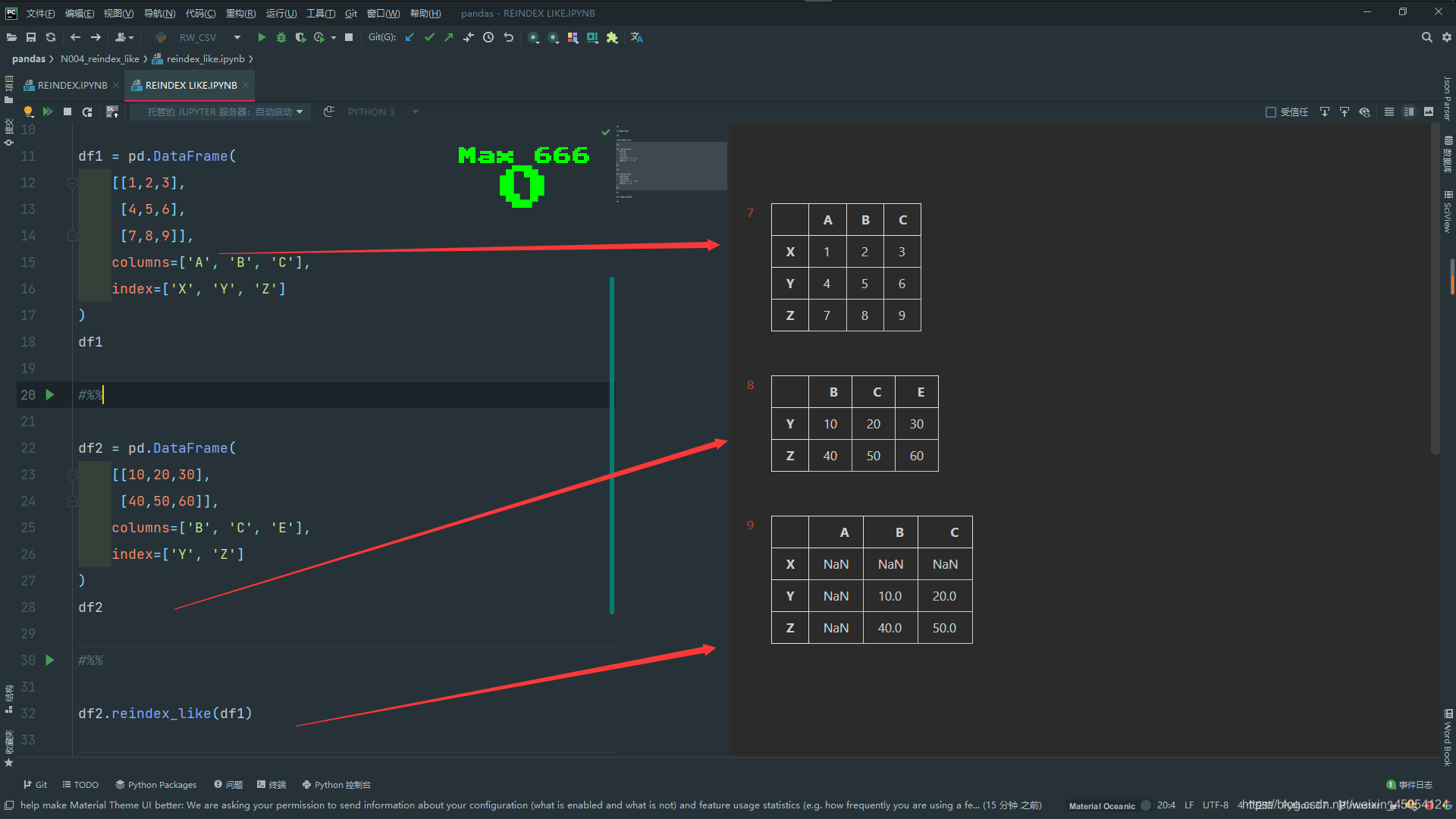
df2 = pd.DataFrame(
[[10,20,30],
[40,50,60]],
columns=['B', 'C', 'E'],
index=['Y', 'Z']
)
df2
#%%
# 使用df2的数据 使用df1的索引
df2.reindex_like(df1)
#%%
rename()重命名索引
代码实例 用到方法
df.rename(columns={‘A’: ‘AA’, ‘B’: ‘BB’}) 还可以传入函数
- index 修改行索引
- columns 修改列索引
- axis =1 时为列索引 =0时行索引
- inplace 默认False 是否将修改运用到原数据 使用的话就不需要重新赋值了
- level 重命名多层索引
#%%
# rename() 重命名索引
#%%
import pandas as pd
#%%
# 创建列行引为1层 行索引为2层的df
df = pd.DataFrame(
[[1,2],
[3,4]],
columns=pd.MultiIndex.from_tuples([('A', 'A'), ('A', 'B')])
)
df
#%%
# 修改列索引为AA BB 传入dict 俩层A都被修改
df.rename(columns={'A': 'AA', 'B': 'BB'})
#%%
# 同理 修改列索引 俩层A都被修改
df.rename({'A': 'AA', 'B': 'BB'}, axis=1)
#%%
# 修改多层列索引 指定level为1 修改为AA BB 只修改第1层 下标0起始
df.rename({'A': 'AA', 'B': 'BB'},
axis=1,
level=1
)
#%%
# 修改行索引为 00
df.rename(index={0: '00'})
#%%
# 查看行索引 类型
df.index
#%%
# 传入函数 修改为str类型 并且原地修改
df.rename(index=str, inplace=True)
#%%
# 再次查看index
df.index
时间相关
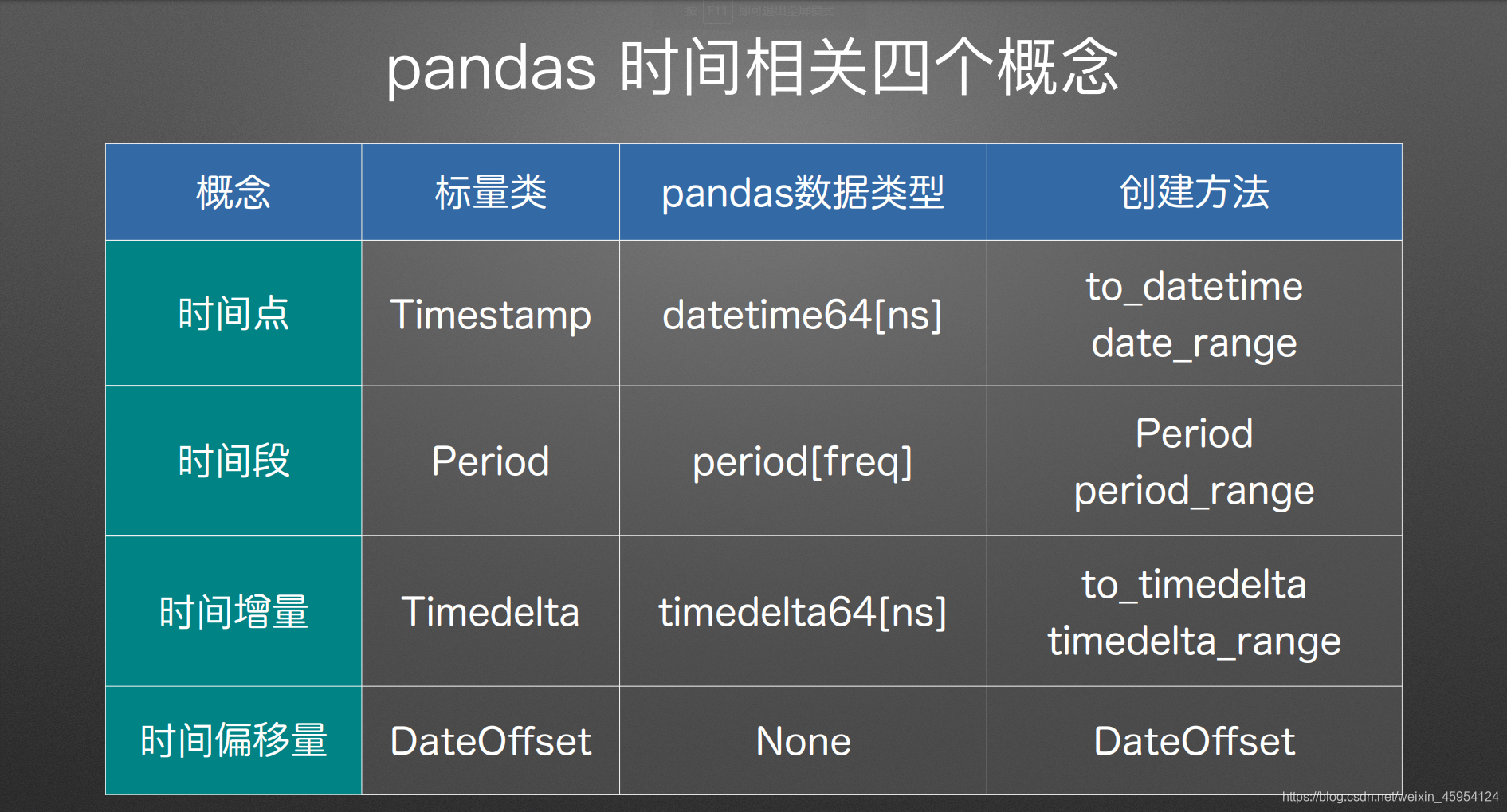


time_series 指定日期类型
datetime64[ns] # 时间戳 秒后还有9位 不展示而已
period[D] # 时间段 天的类型
Timedelta(days=-1) # 绝对的持续时间 正常的一天
DateOffset(days=-1) # 相对的持续时间 工作日
offsets.BDay() # 同上 工作日
#%% pandas 时间 四个概念
import pandas as pd
#%% Timestamp 时间戳
s1 = pd.Series([
'2020-01-01',
'2020-01-02',
], dtype='datetime64[ns]',
name='Timestamp')
s1
#%%
#
s1[0]
#%% Period 时间段
s2 = pd.Series([
'2020-01-01',
'2020-01-02',
], dtype='period[D]',
name='Period')
s2
#%%
s2[0]
#%% 绝对的持续时间
s3 = pd.Series([
pd.Timedelta(days=-1),
pd.Timedelta(days=2),
], name='Timedelta')
s3
#%%
s3[1]
#%% 相对的持续时间
s4 = pd.Series([
pd.DateOffset(days=-1),
pd.DateOffset(days=2),
], name='DateOffset')
s4
#%%
s5 = pd.Series([
pd.offsets.BDay(),
pd.offsets.BDay() * 2,
], name='offsets_BDay')
s5
#%%
# 添加 正常天相加减
s1 + s3
#%%
# 根据工作日相加减
# 注意 这里会有一个警告 Adding/subtracting array of DateOffsets to DatetimeArray not vectorized 意思时间和obj计算 影响性能
s1 + s4
#%%
# 同上
s1 + s5
#%%
# 拼接一个df 查看其类型
df = pd.concat(
[s1, s2, s3, s4, s5],
axis=1
)
df
#%%
# 输出为excel
df.to_excel('tb.xlsx', index=False)
#%%
# 再次读取发现类型改变 指定类型 绝对/相对持续时间为object类型 不可指定类型 只能通过正则这一类的方式进行读取关键字
df1 = pd.read_excel(
'tb.xlsx',
dtype={
'Timestamp': 'datetime64[ns]',
'Period': 'Period[D]',
'Timedelta': 'timedelta64[D]'
}
)
df1
#%%
# 查看类型
df1.dtypes
#%%
# 转变为最有可能的类型 发现变为String类型
df1 = df1.convert_dtypes()
df1
#%%
df1.dtypes
#%%to_datetime() 将对象转换为日期格式
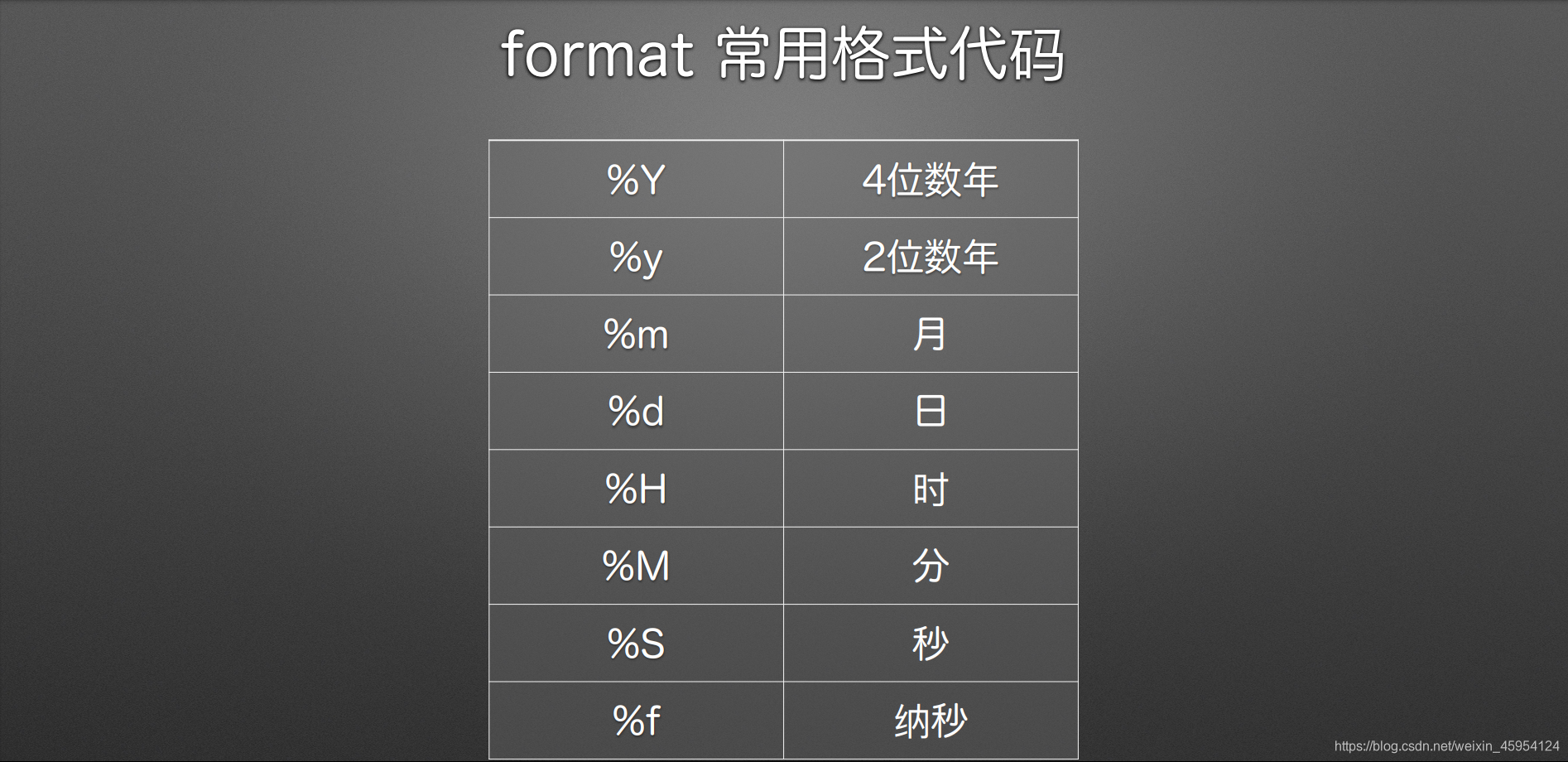
转换第一个参数 arg 为 datetime 日期时间格式
pandas.to_datetime(
arg, # str, 1d list-like
errors=’raise’, # 转换不成功的⾏为 ‘raise’: 抛异常 ‘ignore’: 返回输⼊ ‘coerce’: 转成 NaT
format=None # strftime解析, eg:’%d/%m/%Y’
)
#%%
import pandas as pd
#%%
# 可以转换
pd.to_datetime(
'2020-01-02 03:04:05.123456789')
#%%
# 都可以自动识别为日期格式
pd.to_datetime([
'2020-01-02',
'2020/01/02',
'2020.01.02',
'20200102',
])
#%%
# 传入Series也没问题 也会转换
pd.to_datetime(pd.Series([
'2020-01-02',
'2020/01/02',
'2020.01.02',
'20200102',
]))
#%%
# 报错 ParserError: Unknown string format: 2020#01#02
pd.to_datetime(pd.Series([
'2020-01-02',
'2020#01#02'
]))
#%%
# 报错 效果同上 输出报错内容 Unrecognized value type: <class 'str'>
pd.to_datetime(pd.Series([
'2020-01-02',
'2020#01#02'
]), errors='raise')
#%%
# 不报错 原样输出 但是不会解析为时间格式了 一个不被解析其它都不解析
s = pd.to_datetime(pd.Series([
'2020-01-02',
'2020#01#02'
]), errors='ignore')
s
#%%
# 这是发现还是 str类型
type(s[0])
#%%
# 原样输出字符串
s[1]
#%%
# 将解析不了 报错的转换为NaT
s = pd.to_datetime(pd.Series([
'2020-01-02',
'2020#01#02'
]), errors='coerce')
s
#%%
# 发现是时间格式
s[0]
#%%
# 输出NaT
s[1]
#%%
# 自定义转换
s = pd.to_datetime(pd.Series([
'2020#01#01',
'2020#01#02'
]), format='%Y#%m#%d')
s
date_range()生成时间戳范围


返回固定频率的DatetimeIndex
pandas.date_range(
start=None, # 开始时间
end=None, # 结束时间
periods=None, # 序列⻓度
freq=None, # 频率
)

#%%
import pandas as pd
from datetime import datetime
#%%
data = [
datetime(2020, 1, 1),
datetime(2020, 1, 2),
datetime(2020, 1, 3),
datetime(2020, 1, 4),
datetime(2020, 1, 5),
]
data
#%%
# 指定索引
pd.Index(data)
#%%
# 指定日期索引
pd.DatetimeIndex(data)
#%%
# 创建日期 开始 结束 间隔
pd.date_range(
start='2020-01-01',
end='2020-01-05',
freq='D'
)
#%%
# 开始 结束 一共5等份平分
pd.date_range(
start='2020-01-01',
end='2020-01-05',
periods=5
)
#%%
# 开始 5份 日
pd.date_range(
start='2020-01-01',
periods=5,
freq='D'
)
#%%
# 结束 5份 日
pd.date_range(
end='2020-01-05',
periods=5,
freq='D'
)
#%%
# 开始 5份
pd.date_range(
start='2020-01-01',
periods=5,
freq='W'
)
#%%
# 开始 5份 周一
pd.date_range(
start='2020-01-01',
periods=5,
freq='W-MON'
)
#%%
# 开始 12份 每月末
pd.date_range(
start='2020-01-01',
periods=12,
freq='M'
)
#%%
# 开始 12份 月头
pd.date_range(
start='2020-01-01',
periods=12,
freq='MS'
)
#%%
# 开始 3份 偏移3的月头 1 3 7
pd.date_range(
start='2020-01-01',
periods=3,
freq='3MS'
)
#%%
# 开始 3份 1小时30分钟10秒
pd.date_range(
start='2020-01-01',
periods=3,
freq='1H30min10S'
)
多表合并
append() 上下合并
Series
Series.append(
self,
to_append, # Series 连接对象
ignore_index = False, # 是否重置索引
verify_integrity = False # 是否检查重复索引
) -> Series

DataFrame
DataFrame.append(
self,
other, # Series/DataFrame/dict 连接对象
ignore_index = False, # 是否重置索引
verify_integrity = False, # 是否检查重复索引
sort = False # 是否排序
) -> DataFrame
#%%
import pandas as pd
#%%
df1 = pd.DataFrame(
[[1, 2],
[3, 4]],
columns=['B', 'A'],
index=['x', 'y']
)
df1
#%%
s = pd.Series(
[5, 6],
index=['B', 'A'],
name='z')
s
#%%
# df添加series对象
df1.append(s)
#%%
# 创建df
df2 = pd.DataFrame(
[[5, 6]],
columns=['B', 'C'],
index=['z']
)
#%%
df1
#%%
df2
#%%
# df 添加 df
df1.append(df2)
#%%
# 添加多个df
df1.append([df2, df1])
#%%
# 添加df 排序
df1.append(df2, sort=True)
#%%
# 检测是否有重复索引
# df1.append(
# df1,
# verify_integrity=True)
#%%
# 添加df 重置索引
df1.append(
df1,
ignore_index=True)
#%%
df1
#%%
# 添加字典 重置索引
df1.append({'A': 5, 'B': 6},
ignore_index=True)
实战练习
"""
使用 append() 函数
合并一个文件夹里面的全部表格
"""
import os
import pandas as pd
# 定义函数 指定类型 指定返回格式
def v_concat_files(folder: str) -> pd.DataFrame:
# 创建一个空df 用来存储所有
df_all = pd.DataFrame()
# 循环遍历路径
for fn in os.listdir(folder):
# 拼接路径
ffn = os.path.join(folder, fn)
# 读取数据
df_temp = pd.read_excel(ffn)
# 进行拼接
df_all = df_all.append(df_temp)
return df_all
if __name__ == '__main__':
# 路径
# df_A = v_concat_files(
# '/Users/Yi/Mirror/我的python教程/Pandas办公自动化/z_data_source/PlatformA'
# )
# 查看df详细信息
# df_A.info()
# 查看头几行
# print(df_A.head())
# 输出命名为all_A的Excel
# df_A.to_excel('all_A.xlsx')
# 增加字段 平台
# df_A['平台'] = '平台A'
# 上下文管理操作Excel文件 路径 修改日期格式
# with pd.ExcelWriter(
# 'all_A.xlsx',
# datetime_format='YYYY-MM-DD'
# ) as writer:
# 输出Excel all_A.xlsx为修改后的writer 不设置索引
# df_A.to_excel(writer, index=False)
# 平台B 同理
df_B = v_concat_files(
'/Users/Yi/Mirror/我的python教程/Pandas办公自动化/z_data_source/PlatformB'
)
df_B['平台'] = '平台B'
with pd.ExcelWriter(
'all_B.xlsx',
datetime_format='YYYY-MM-DD'
) as writer:
df_B.to_excel(writer, index=False)
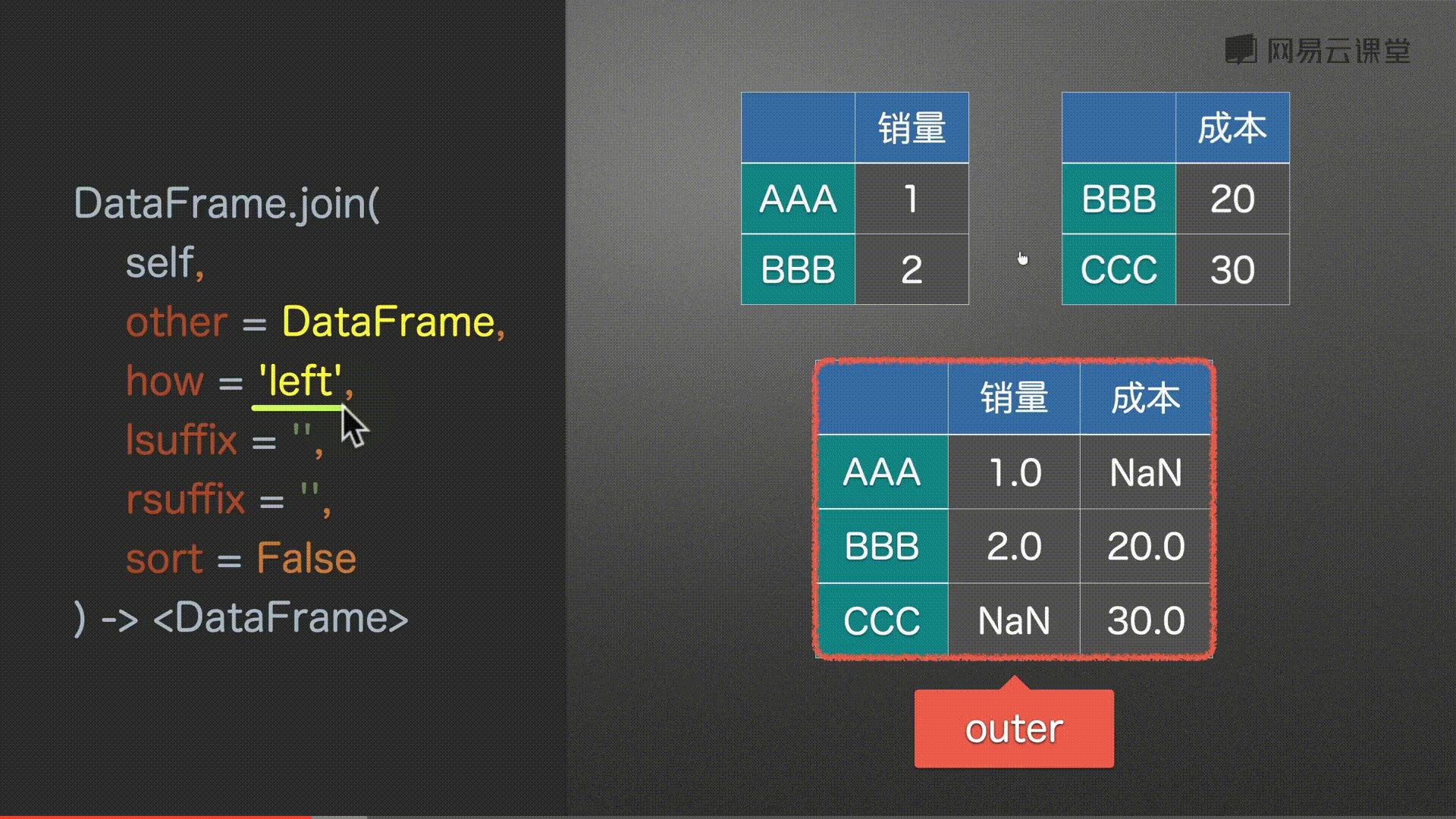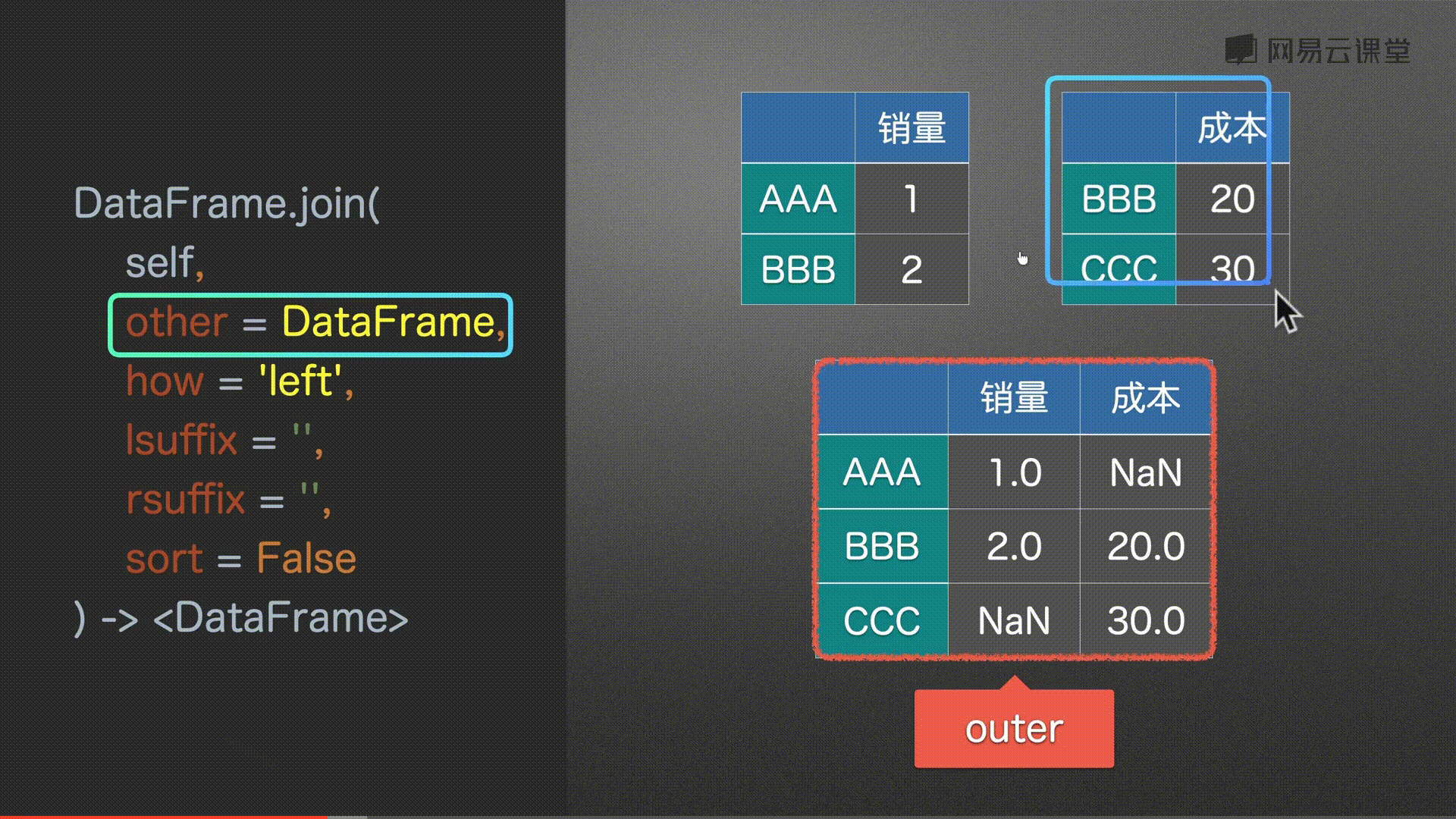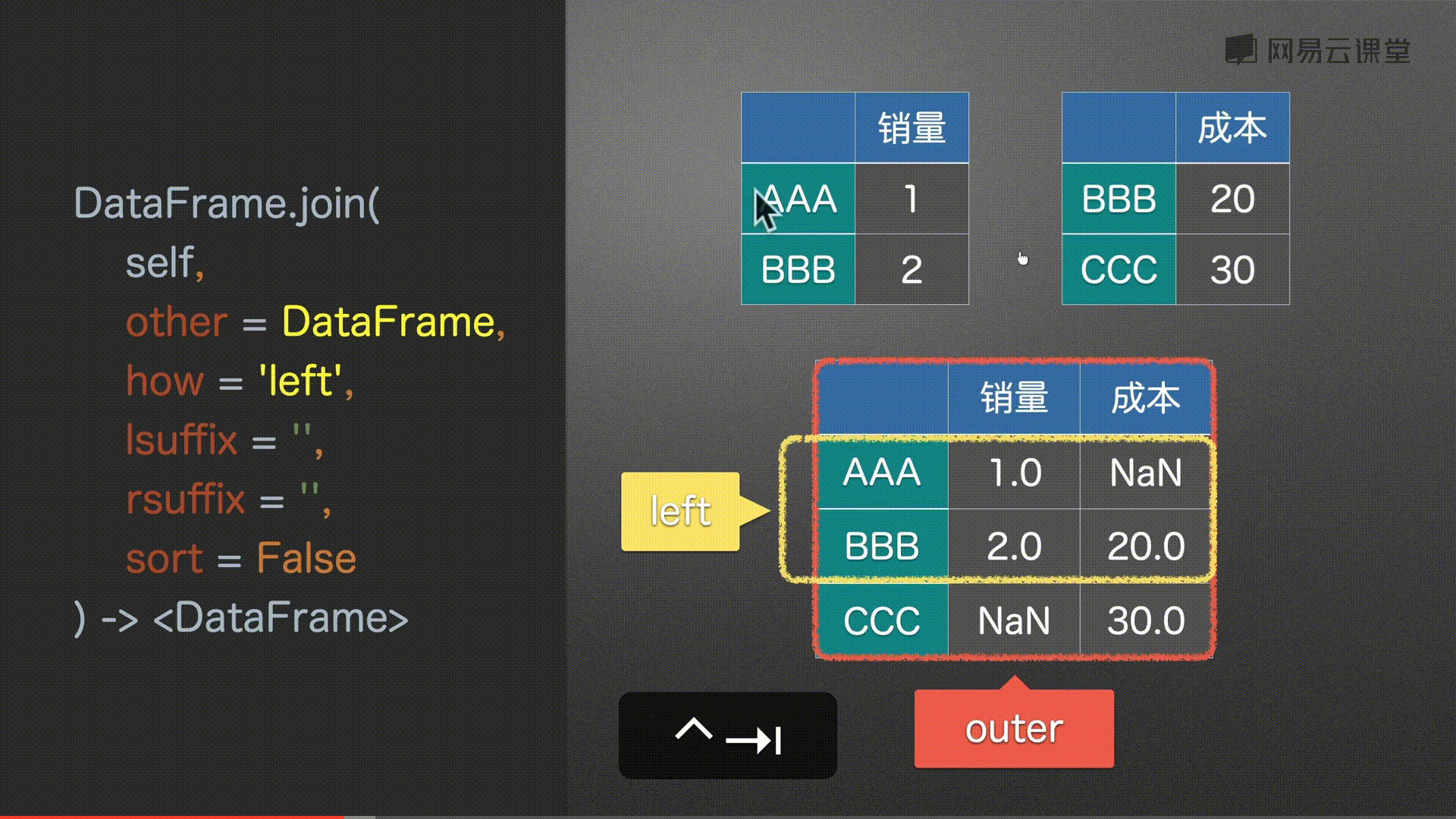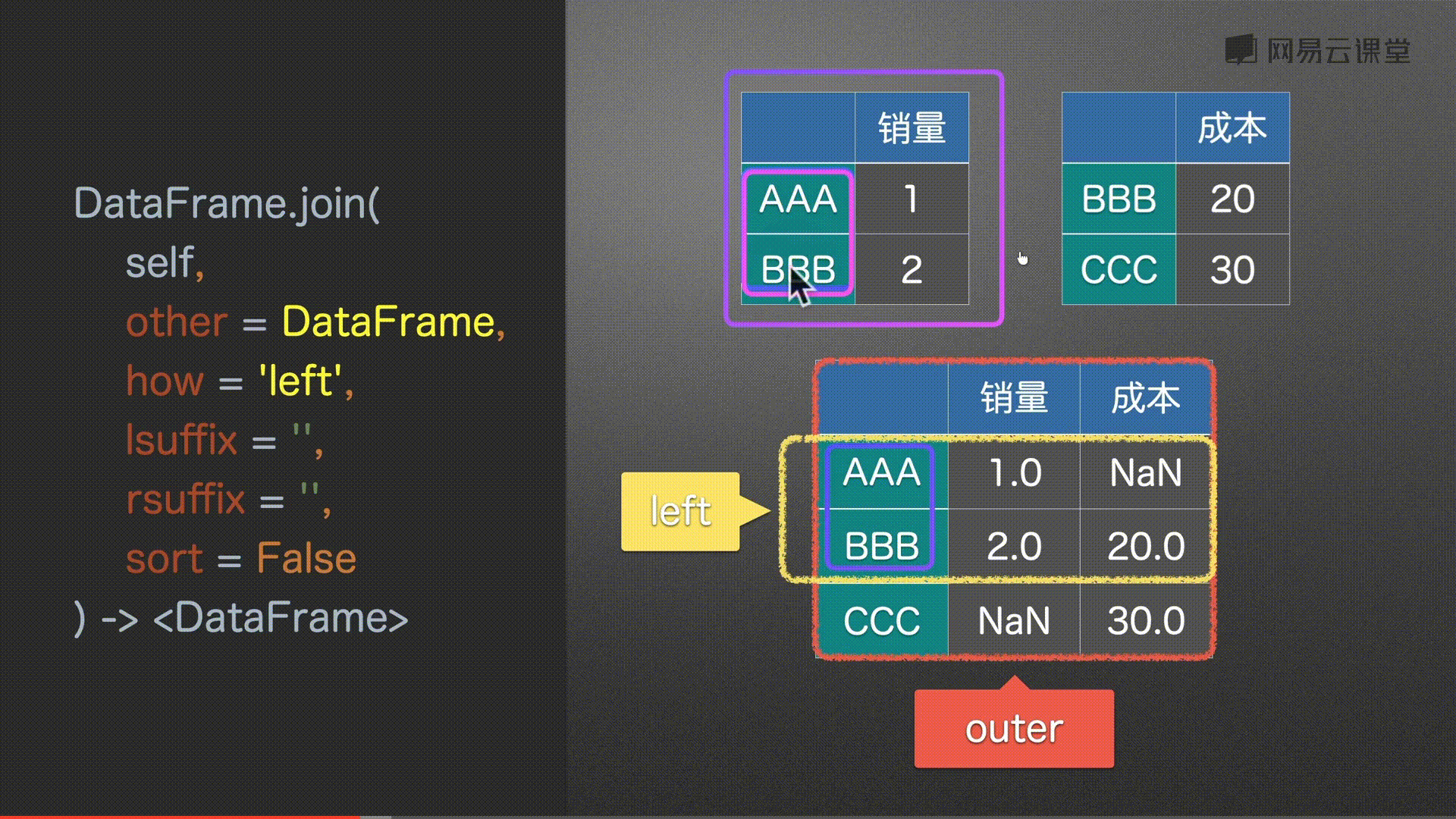
join() 左右合并
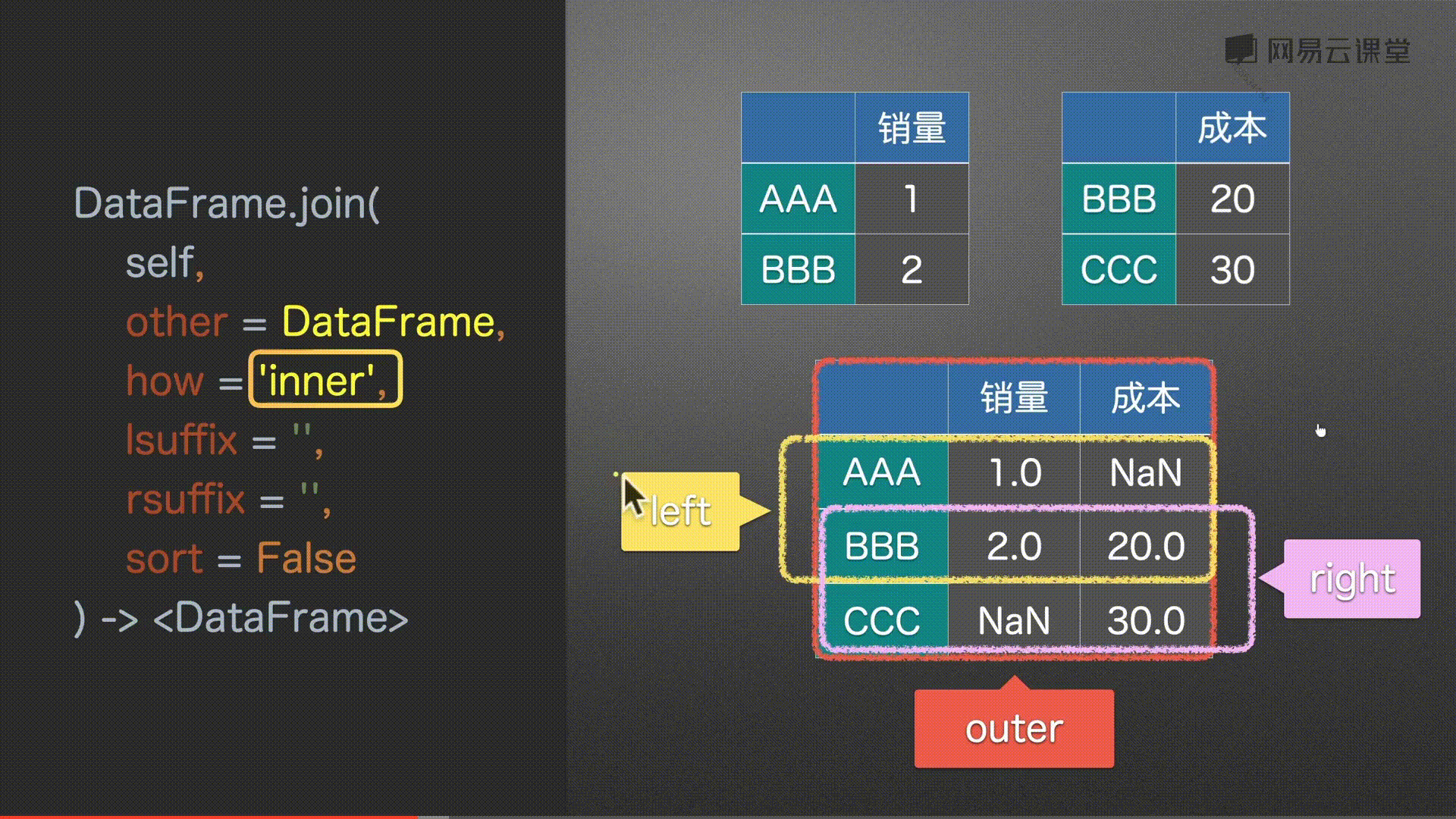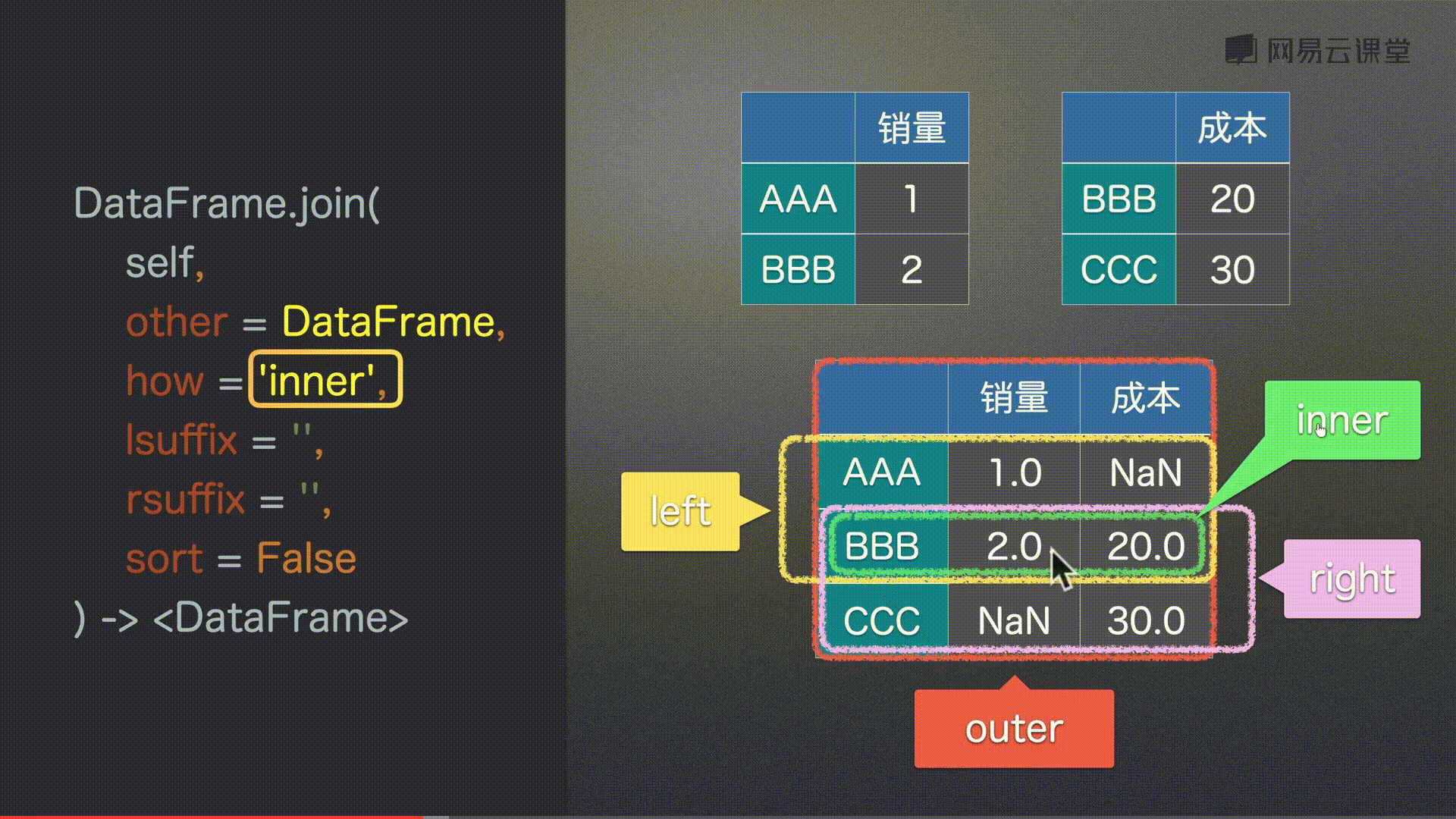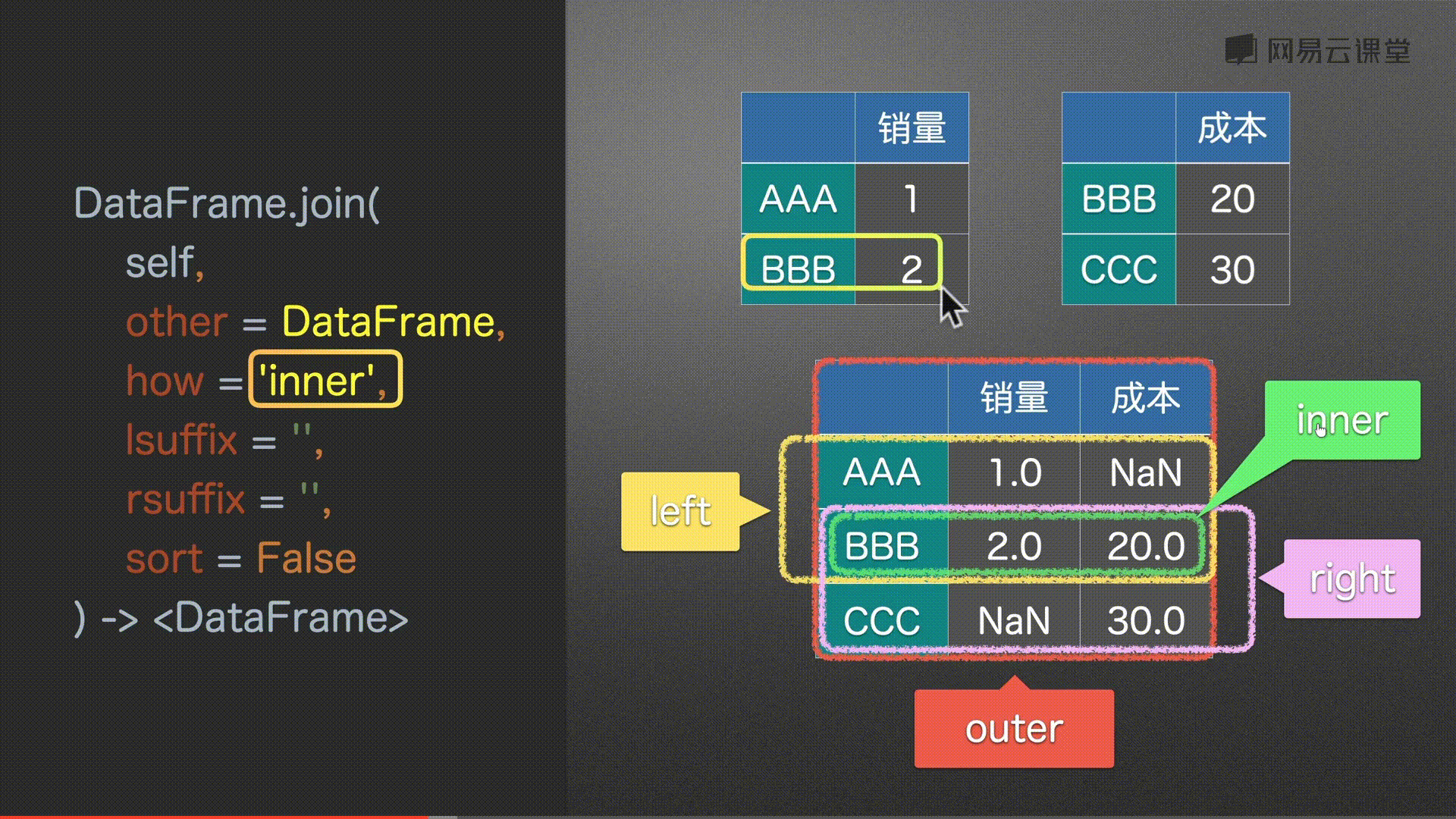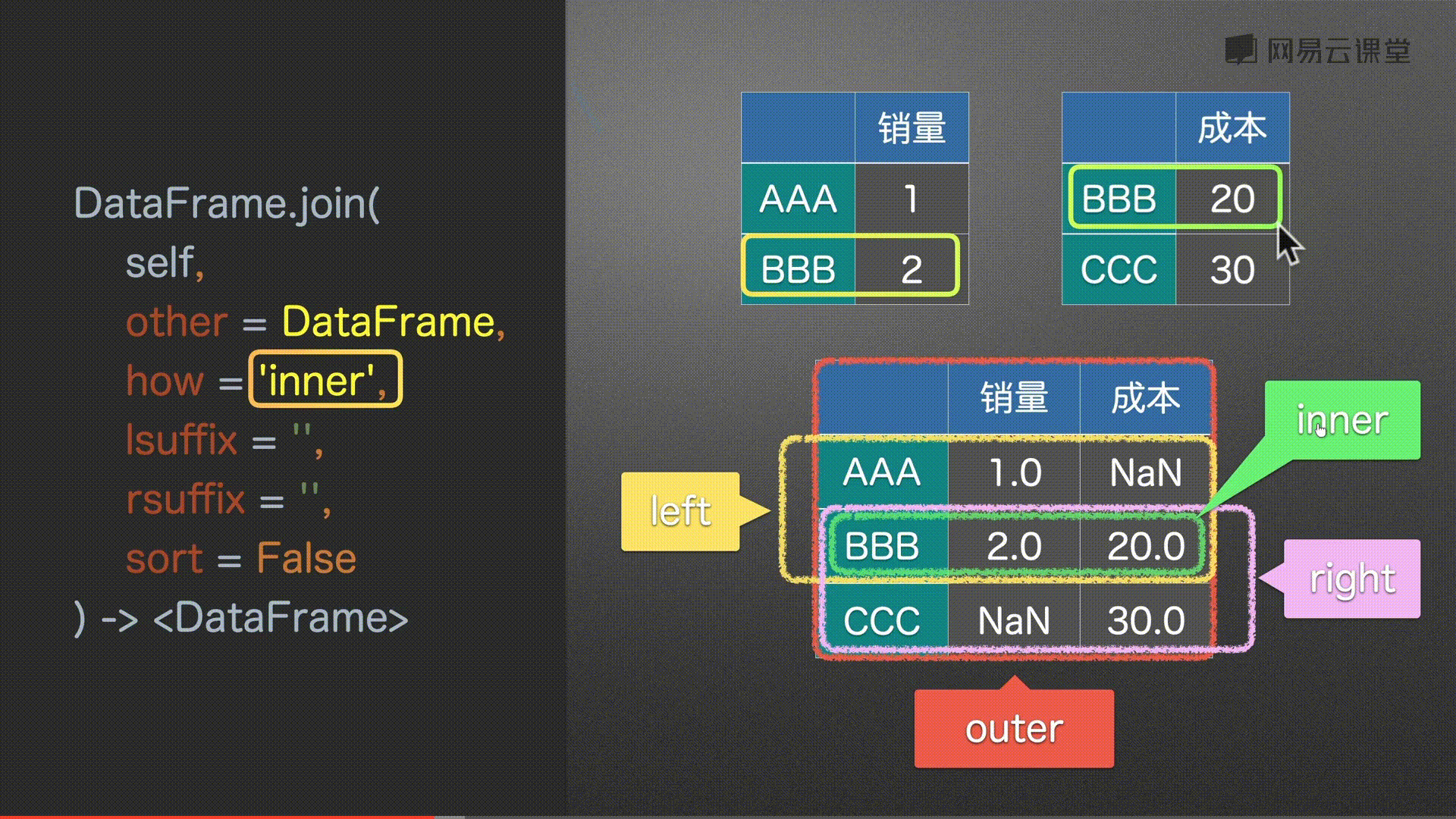
DataFrame
DataFrame.join(
self,
other, # Series/DataFrame/list of DataFrame 传入对象
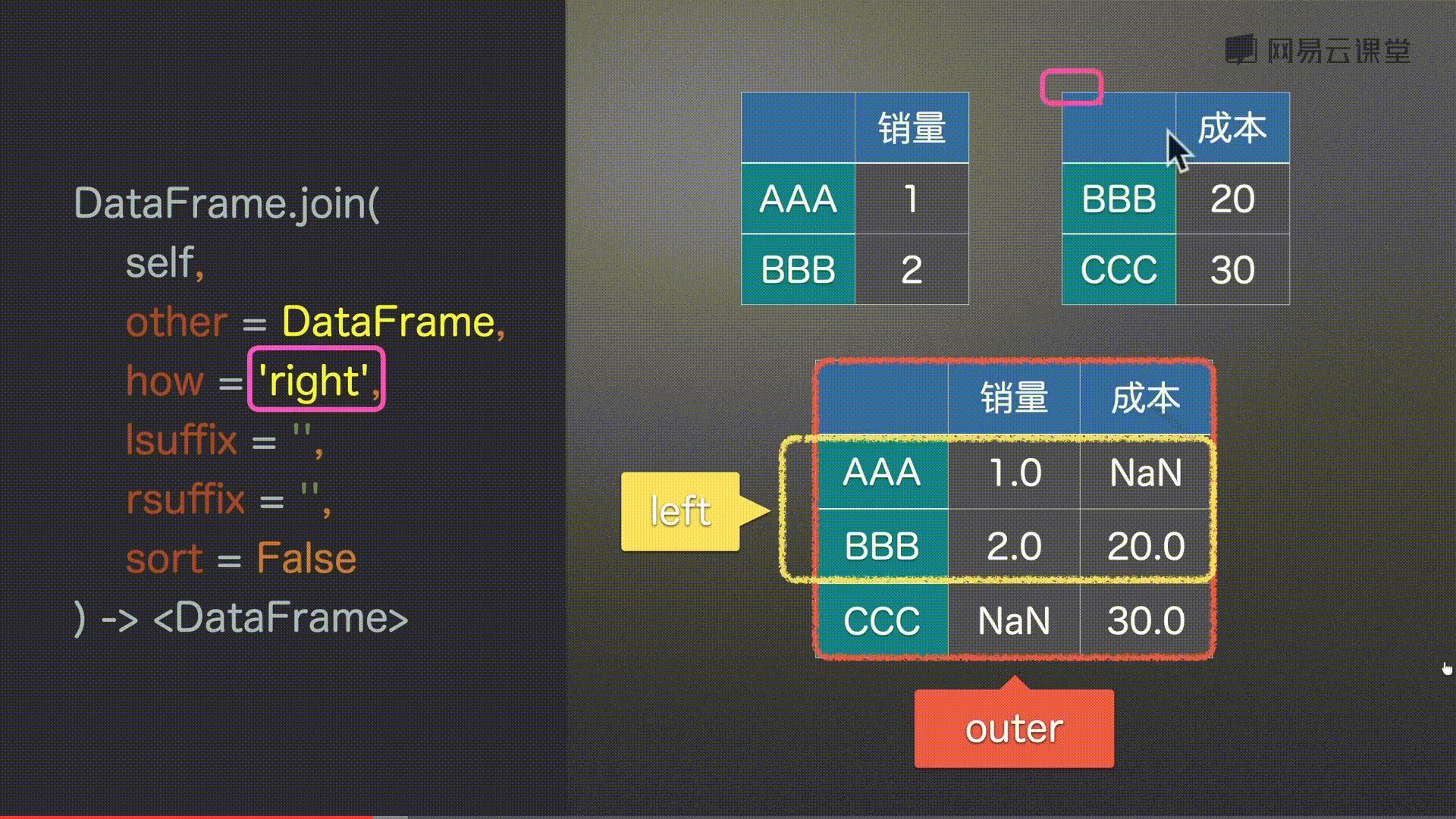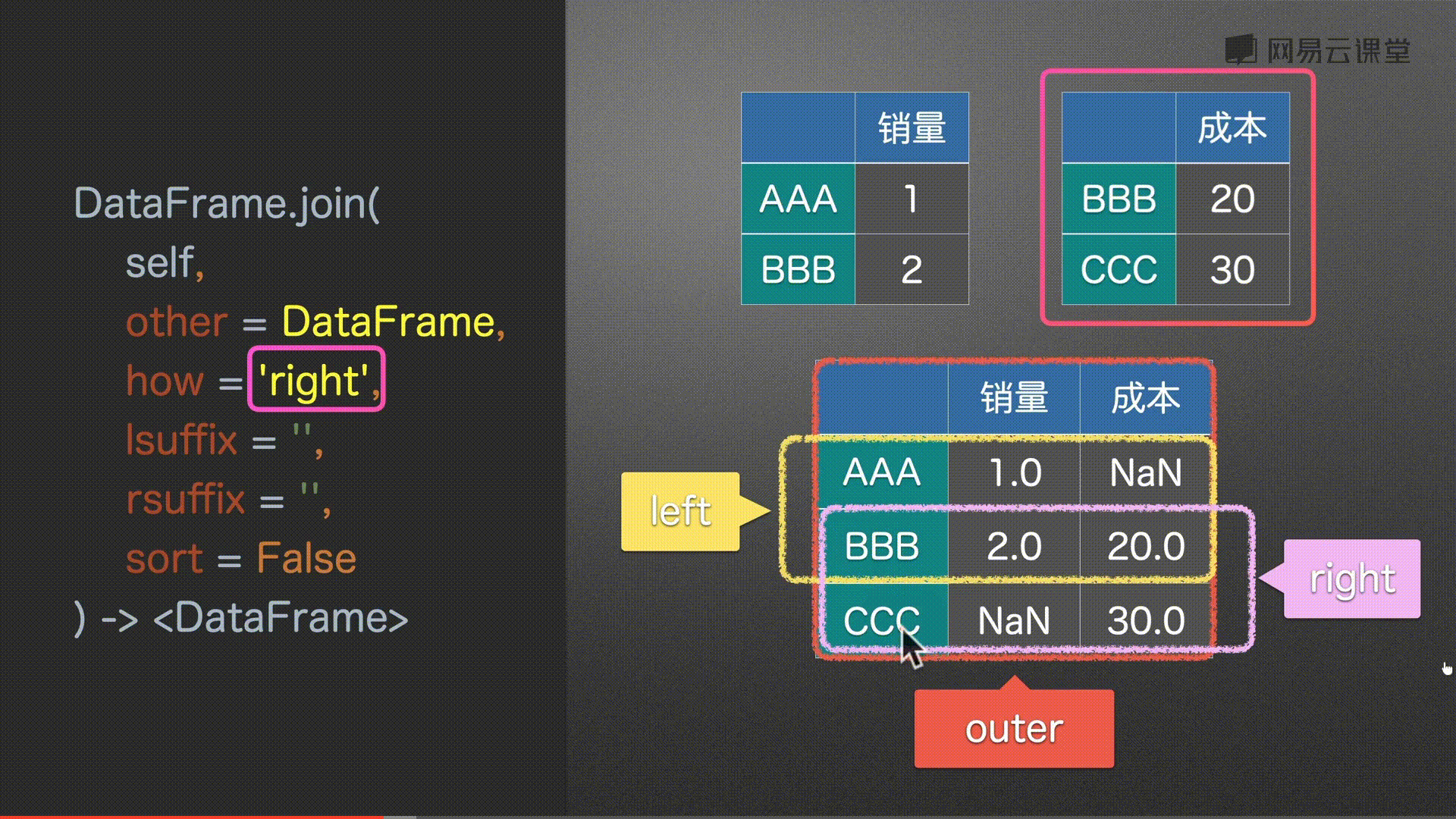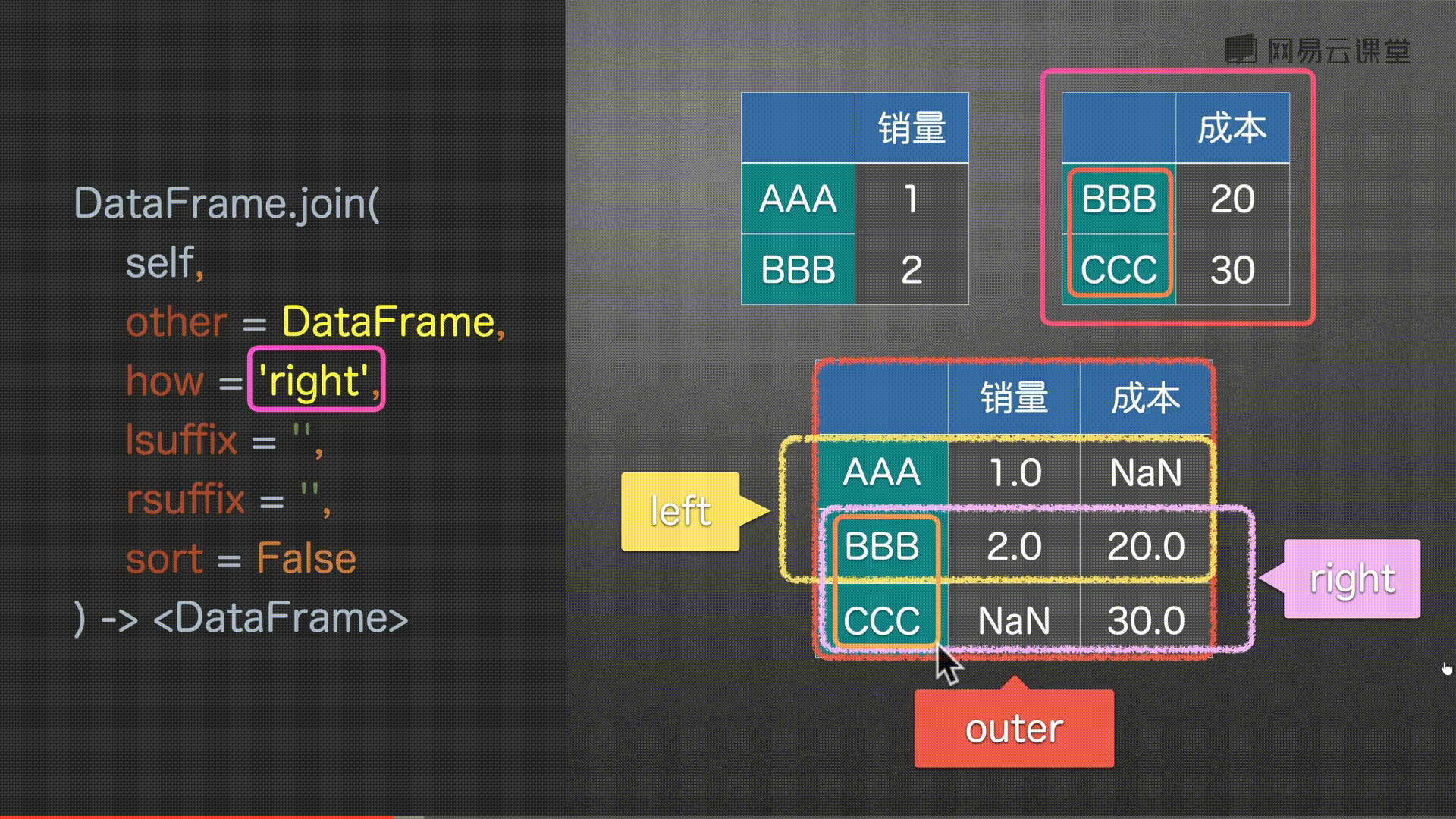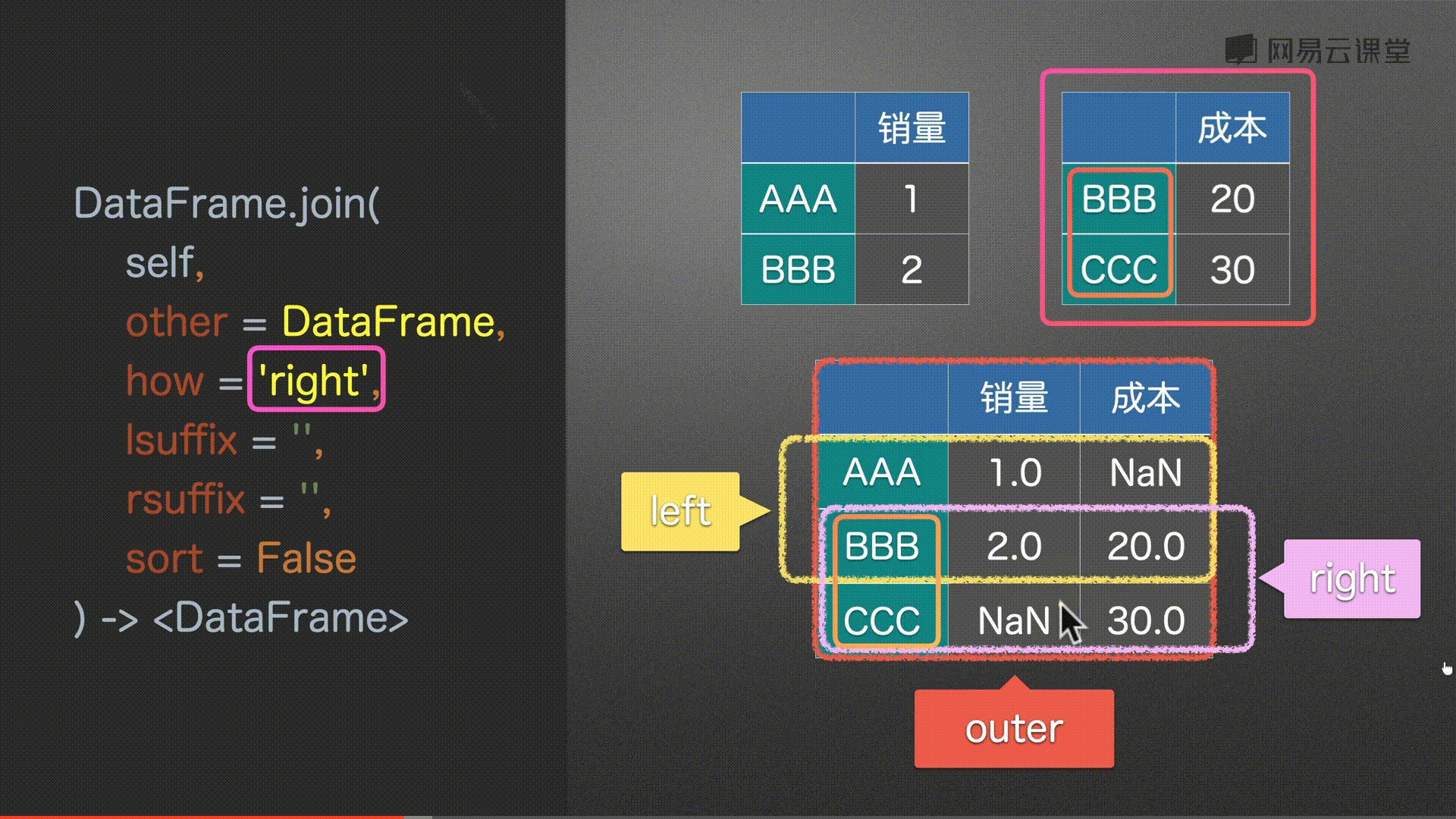
how = ‘left’, # {‘left’, ‘right’, ‘outer’, ‘inner’} # 左 右 并集 交集
lsuffix = ‘’ , # 左表数据名
rsuffix = ‘’ , # 右表数据名
sort = False # 排序
) -> DataFrame
other = Series

how = ‘left’, # {‘left’, ‘right’, ‘outer’, ‘inner’} # 左 右 并集 交集

#%%
import pandas as pd
#%%
df = pd.DataFrame({
'A': [1, 2],
}, index=['x', 'y'])
df
#%%
s = pd.Series(
[10, 20],
index=['x', 'y'],
name='B'
)
s
#%%
# 拼接Series对象
df.join(s)
#%%
df0 = pd.read_excel(
'join.xlsx',
index_col=0,
sheet_name=0
)
df0
#%%
df1 = pd.read_excel(
'join.xlsx',
index_col=0,
sheet_name=1
)
df1
#%%
# df拼接df 默认以左为主
df0.join(df1)
#%%
# df拼接df 排序
df0.join(df1, sort=True)
#%%
df0 = pd.read_excel(
'join.xlsx',
sheet_name=0
)
df0
#%%
df1 = pd.read_excel(
'join.xlsx',
sheet_name=1
)
df1
#%%
# df拼接df 有重复列索引 自己的索引后加上相应的后缀
df0.join(
df1,
lsuffix='_l',
rsuffix='_r',
)
#%%
df0 = pd.read_excel(
'join.xlsx',
index_col=0,
sheet_name=0
)
df0
#%%
df2 = pd.read_excel(
'join.xlsx',
index_col=0,
sheet_name=2
)
df2
#%%
# 默认以左为主
df0.join(df2)
#%%
# 同上 没有补充NaN
df0.join(df2, how='left')
#%%
# 取所有 没有补充NaN
df0.join(df2, how='outer')
#%%
# 以右为主 没有补充NaN
df0.join(df2, how='right')
#%%
# 取并集 没有补充NaN
df0.join(df2, how='inner')
#%%
df0
#%%
# 重置索引
df1 = df1.set_index('货号')
df1
#%%
df2
#%%
# 默认以左为主 多个拼接
df0.join([df1, df2])
#%%
# 多个拼接 所有字段
df0.join([df1, df2], how='outer')
concatt 连接/合并表格
pandas.concat(
objs, # 序列, 字典
axis=0, # 设置轴
join=’outer’, # {‘outer’,’inner’}
keys=None, # 设置最外层的索引
ignore_index=False, # 是否忽略旧表索引
verify_integrity=False # 是否检查有重叠索引
) -> <Series/Data
#%%
import pandas as pd
#%%
s1 = pd.Series([1, 2], name='A')
s1
#%%
s2 = pd.Series([1, 2], name='B')
s2
#%%
# 合并俩个Series
pd.concat([s1, s2])
#%%
# 设置索引不重复
pd.concat([s1, s2],
ignore_index=True)
#%%
# axis默认为0也就是上下拼接 我们设置为1左右拼接
pd.concat([s1, s2],
axis=1)
#%%
# 读取Excel 有多个sheet_name 结果为dict
df_dict = pd.read_excel(
'concat_0.xlsx',
sheet_name=None
)
df_dict
#%%
df_dict['1月']
#%%
df_dict['2月']
#%%
df_dict['3月']
#%%
# 拼接三个DF
pd.concat([
df_dict['1月'],
df_dict['2月'],
df_dict['3月'],
], ignore_index=True)
#%%
# 拼接三个DF设置索引
df = pd.concat([
df_dict['1月'],
df_dict['2月'],
df_dict['3月'],
], keys=['1月', '2月', '3月'])
df
#%%
df.loc['2月']
#%%
# 直接传入dict 进行拼接 结果是一样的
df1 = pd.concat(df_dict)
df1
#%%
# 查看结果是否相同 发现全部为Ture
df == df1
#%%
# 读取Excel 指定第0列为索引
df_dict = pd.read_excel(
'concat_1.xlsx',
sheet_name=None,
index_col=[0]
)
df_dict
#%%
# 单独取出是一个DF
df_dict['销量']
#%%
# 左右合并 默认并集
df = pd.concat([
df_dict['销量'],
df_dict['成本'],
df_dict['库存'],
], axis=1)
#%%
# 左右合并 指定join 为交集
pd.concat([
df_dict['销量'],
df_dict['成本'],
df_dict['库存'],
], axis=1, join='inner')
#%%
df
#%%
# DF和Series进行合并 会有重复索引
pd.concat([df, df['库存']],
axis=1)
#%%
# 检查是否有重复索引 有的话抛出异常
pd.concat([df, df['库存']],
axis=1,
verify_integrity=True)
merge() 联接合并
merger使用还是比较常见的 建议多看看
官网有四种合并方式 一对一 多对一 一对多 多对多 实际有三种 一对一 多对一 多对多
DataFrame.merge(right, how=’inner’, on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=(‘_x’, ‘_y’), copy=True, indicator=False, validate=None)
#%%
import pandas as pd
#%%
df1 = pd.read_excel('sales.xlsx')
df1
#%%
df2 = pd.read_excel('goods_base.xlsx')
df2
#%%
# 常用的只有几种参数组合 看官网
pd.merge(df1, df2,
on='货号',
how='left',
validate='m:1')
#%%
import pandas as pd
#%%
df1 = pd.read_excel(
'on_index.xlsx',
index_col=[0]
)
df1
#%%
df2 = pd.read_excel(
'on_index.xlsx',
sheet_name=1,
index_col=[0]
)
df2
#%%
pd.merge(df1, df2,
left_index=True,
right_index=True,
how='outer')
#%%
df1.join(df2, how='outer')
#%%
df3 = pd.read_excel(
'on_list.xlsx'
)
df3
#%%
df4 = pd.read_excel(
'on_list.xlsx',
sheet_name=1
)
df4
#%%
pd.merge(df3, df4,
on=['年份', '月份'])where() 使用条件选择数据
#%%
# where()
#%%
import pandas as pd
import numpy as np
#%%
df = pd.DataFrame(
{
'货号': ['a', 'b', 'c', 'd'],
'活动价': [80, 0, 90, 0],
'原价': [120,130, 140, 150],
}
)
df
#%%
df['实收价'] = df['活动价'].where(
df['活动价'] > 0,
df['原价']
)
df
#%%
df = pd.DataFrame(
{
'货号': ['a', 'b', 'c', 'd'],
'销量': [120,130, 140, 150],
}
)
df
#%%
df['热销度'] = np.where(
df['销量'] > 135,
'畅销',
'平销'
)
df
#%%
df = pd.DataFrame(
{
'货号': ['a', 'b', 'c', 'd'],
'活动价': [80, 0, 90, 0],
'原价': [120,130, 140, 150],
}
)
df
#%%
df['实收价'] = np.where(
df['活动价'] == 0,
df['原价'],
df['活动价']
)
df
#%%cut() 将值分类到离散间隔
#%%
# cut() 将值分类到离散间隔
#%%
import pandas as pd
#%%
df = pd.DataFrame(
{'成绩': [30, 60, 70, 100, 0, 96]}
)
df
#%%
# bins- 指定条件区间 输出结果 [包含 (不包含
# include_lowest 是否包含左的结果
df['等级'] = pd.cut(
df['成绩'],
bins=[0, 60, 80, 100],
include_lowest=True
)
df
#%%
# right=False 不包含最右边结果 默认为Ture
df['等级'] = pd.cut(
df['成绩'],
bins=[0, 60, 80, 100],
right=False,
)
df
#%%
# 这时候发现有点儿小问题 并没有包含60 我们修改值为59.9
df['等级'] = pd.cut(
df['成绩'],
bins=[0, 59.9, 80, 100],
include_lowest=True,
labels=['不及格', '及格', '优秀']
)
df
#%%
# bins=3时阈值(最大值 - 最小值 / 3)
df['等级'] = pd.cut(
df['成绩'],
bins=3,
labels=['差', '中等', '优秀']
)
df
#%%重复值
duplicated 标记Series/DataFrame中重复的值
drop_duplicates 删除Series/DataFrame中重复的值
#%%
# duplicated()
# drop_duplicates()
#%%
import pandas as pd
#%%
s = pd.Series([1, 2, 3, 2, 3, 3])
s
#%%
# 检查重复值 重复为ture 重复的第一个元素是False
s.duplicated(keep='first')
#%%
# 删除重复值 保留第一个元素 也就是删除False
s.drop_duplicates(keep='first')
#%%
# 由后向前检查重复值
s.duplicated(keep='last')
#%%
# 保留最后一个重复值 其它删除
s.drop_duplicates(keep='last')
#%%
# 检查重复值 只要重复都为False
s.duplicated(keep=False)
#%%
# 删除所有重复值
s.drop_duplicates(keep=False)
#%%
df = pd.DataFrame(
{
'A': [1, 2, 2, 2, 3],
'B': [4, 5, 6, 6, 6],
}
)
df
#%%
# 指定检查A列重复值
df.duplicated(subset='A')
#%%
# 指定检查B列重复值
df.duplicated(subset='B')
#%%
# 检查AB列相同的
df.duplicated(subset=['A', 'B'])
#%%
# 删除AB列相同的 保留第一个值
df.drop_duplicates(subset=['A', 'B'])
#%%
# 删除AB列相同 保留第一个值
df.drop_duplicates(
subset=['A', 'B'],
keep='last'
)
#%%
# 删除AB列相同 保留第最后一个值
df.drop_duplicates(
subset=['A', 'B'],
keep=False
)
#%%
# 只要是重复的就删除
df.drop_duplicates(
subset=['A', 'B'],
keep=False,
ignore_index=True
)
#%%
# 默认删除AB列相同的 保留第一个
df.drop_duplicates()
sample() 随机取样
#%%
# sample()
#%%
import pandas as pd
import numpy as np
#%%
s = pd.Series([1,2,3,4,5])
s
#%%
# 随机取三个
s.sample(n=3)
#%%
# 根据传入小数进行取值 0.4取俩个 0.6取三个 1为全部
s.sample(frac=1)
#%%
# 随机取出6个 如果不生成新的对象 则会异常
s.sample(n=6, replace=True)
#%%
# weights进行权重配比 0为不选择
s.sample(n=6,
replace=True,
weights=[10,20,0,0.2,0.8],
random_state=12
)
#%%
df = pd.DataFrame(
np.random.randint(10, size=(3,3)),
columns=list('ABC')
)
df
#%%
# 随机取出俩个 默认行
df.sample(2)
#%%
# 随机取出俩个 指定列
df.sample(2, axis=1)
#%%resample() 重采样
#%%
# resample()
#%%
import pandas as pd
#%%
index = pd.to_datetime([
'2000-01-01 00:01:10',
'2000-01-01 00:02:20',
'2000-01-01 00:03:00',
'2000-01-01 00:04:30',
'2000-01-01 00:05:40',
'2000-01-01 00:06:50',
])
s = pd.Series(range(6), index=index)
s
#%%
# 每隔俩分钟进行平均值
s.resample('2T').mean()
#%%
df = pd.read_excel(
'sales_data_1000.xlsx',
index_col='日期',
parse_dates=True
)
df
#%%
df.dtypes
#%%
# 每隔俩天 进行运算 只会运算数值型
df.resample('2D').agg(
{'售卖价': 'mean',
'客户数': 'sum'}
)
#%%
# 读取excel并将日期解析为索引
df = pd.read_excel(
'sales_data_1000.xlsx',
parse_dates=['日期']
)
df
#%%
df.dtypes
#%%
# 每隔俩天进行重采样 求和
df.resample('2D', on='日期').sum()
#%%
# 指定双重索引
df = df.set_index(['货号', '日期'])
df
#%%
# 进行重采样 指定日期 索引为 0(货号) 1(日期) 每天进行求和
df.resample('D', level=1).sum()
#%%


- Post link: https://yanxiang.wang/pandas%E8%BF%9B%E9%98%B6%E6%93%8D%E4%BD%9C-%E8%AE%A1%E7%AE%97/
- Copyright Notice: All articles in this blog are licensed under unless otherwise stated.