
Django是高水准的Python编程语言驱动的一个开源模型.视图,控制器风格的Web应用程序框架,它起源于开源社区。使用这种架构,程序员可以方便、快捷地创建高品质、易维护、数据库驱动的应用程序。这也正是OpenStack的Horizon组件采用这种架构进行设计的主要原因。另外,在Dj ango框架中,还包含许多功能强大的第三方插件,使得Django具有较强的可扩展性 。
ModelViewSet源码分析
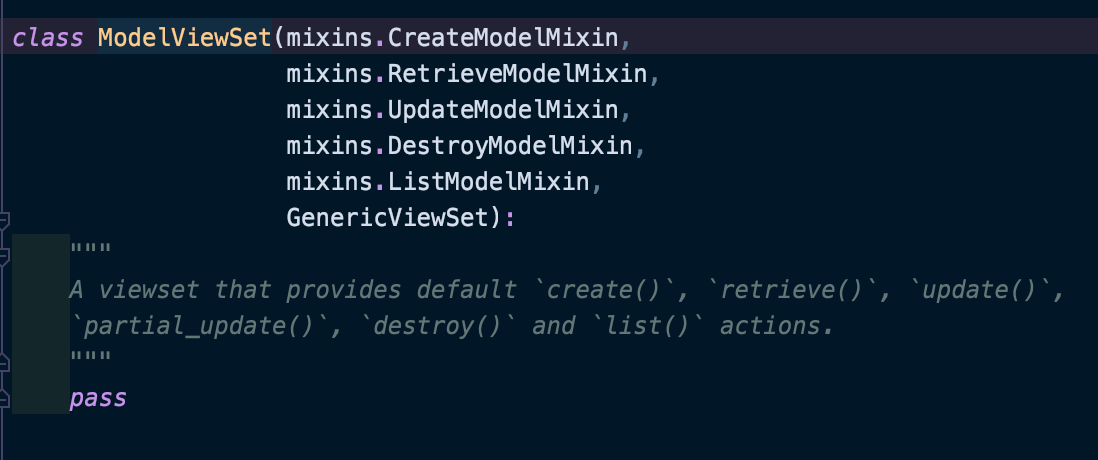
继承两种类
首先看到 ModelViewSet 主要继承两种类
- Mixin 混合类
- GenericViewSet
我们先看Mixin 混合类
Mixin 混合类
mixin混合类是一种通用语言的设计模式,在python中指的就是多重继承。
CreateModelMixin
创建、添加、新增
class CreateModelMixin:
"""
Create a model instance.
"""
def create(self, request, *args, **kwargs):
# 参数获取以及反序列化
serializer = self.get_serializer(data=request.data)
# 参数校验
serializer.is_valid(raise_exception=True)
# 执行保存命令
self.perform_create(serializer)
# Location 头信息
headers = self.get_success_headers(serializer.data)
# Response 返回
return Response(serializer.data, status=status.HTTP_201_CREATED, headers=headers)
def perform_create(self, serializer):
# 执行保存命令
serializer.save()
def get_success_headers(self, data):
try:
return {'Location': str(data[api_settings.URL_FIELD_NAME])}
except (TypeError, KeyError):
return {}可以看到其中有 perform_create 方法,我们一般重新是不需要重写 create 方法的,重新 perform_create即可。其它同理
RetrieveModelMixin
获取单个实例信息
class RetrieveModelMixin:
"""
Retrieve a model instance.
"""
def retrieve(self, request, *args, **kwargs):
# 获取当前实例
instance = self.get_object()
# 序列化
serializer = self.get_serializer(instance)
#
return Response(serializer.data)UpdateModelMixin
class UpdateModelMixin:
"""
Update a model instance.
"""
def update(self, request, *args, **kwargs):
# 获取参数中是否存在 partial 参数,默认局部更新,True 为全量更新
partial = kwargs.pop('partial', False)
# 获取当前实例
instance = self.get_object()
# 修改反序列化
serializer = self.get_serializer(instance, data=request.data, partial=partial)
# 数据格式校验
serializer.is_valid(raise_exception=True)
# 执行保存命令 save
self.perform_update(serializer)
# 注释:如果'prefetch_related'已经应用到一个查询集,我们需要
# 强制取消实例上的预取缓存。
if getattr(instance, '_prefetched_objects_cache', None):
# If 'prefetch_related' has been applied to a queryset, we need to
# forcibly invalidate the prefetch cache on the instance.
instance._prefetched_objects_cache = {}
return Response(serializer.data)
def perform_update(self, serializer):
serializer.save()
def partial_update(self, request, *args, **kwargs):
# 使用局部更新
kwargs['partial'] = True
return self.update(request, *args, **kwargs)DestroyModelMixin
class DestroyModelMixin:
"""
Destroy a model instance.
"""
def destroy(self, request, *args, **kwargs):
# 获取当前实例
instance = self.get_object()
# 执行删除操作
self.perform_destroy(instance)
# 返回响应
return Response(status=status.HTTP_204_NO_CONTENT)
def perform_destroy(self, instance):
instance.delete()ListModelMixin
class ListModelMixin:
"""
List a queryset.
"""
def list(self, request, *args, **kwargs):
# 获取当前实例
# 有条件则根据条件进行筛选
queryset = self.filter_queryset(self.get_queryset())
# 分页
page = self.paginate_queryset(queryset)
# 是否存在数据
if page is not None:
# 序列化 多个
serializer = self.get_serializer(page, many=True)
# 根据我们定义的 pagination_class 进行返回
return self.get_paginated_response(serializer.data)
# 不需要分页直接返回 多个
serializer = self.get_serializer(queryset, many=True)
return Response(serializer.data)这就是 mixins 混合类当中最常用的几个了,涵盖了增删改查所有逻辑,接下啦看看 GenericViewSet
GenericViewSet
我们在上面的 mixins 混合类中看到了一些实例方法,例如 self.get_queryset() 这些方法都是来自 GenericViewSet 的。
class GenericViewSet(ViewSetMixin, generics.GenericAPIView):
"""
The GenericViewSet class does not provide any actions by default,
but does include the base set of generic view behavior, such as
the `get_object` and `get_queryset` methods.
"""
pass可以看到注释已经解释的相当明确了,它的本质实际是 GenericAPIView
GenericAPIView
class GenericAPIView(views.APIView):
"""
Base class for all other generic views.
"""
# You'll need to either set these attributes,
# or override `get_queryset()`/`get_serializer_class()`.
# If you are overriding a view method, it is important that you call
# `get_queryset()` instead of accessing the `queryset` property directly,
# as `queryset` will get evaluated only once, and those results are cached
# for all subsequent requests.
# 要查询的 queryset 实例 格式为 models.object.all() 或者根据条件
queryset = None
# 我们所需要的序列化
serializer_class = None
# If you want to use object lookups other than pk, set 'lookup_field'.
# For more complex lookup requirements override `get_object()`.
# 默认查询主键 pk
lookup_field = 'pk'
lookup_url_kwarg = None
# The filter backend classes to use for queryset filtering
# 过滤筛选条件 需要使用到 django-filter 包
filter_backends = api_settings.DEFAULT_FILTER_BACKENDS
# The style to use for queryset pagination.
# 分页处理 默认使用全局配置
pagination_class = api_settings.DEFAULT_PAGINATION_CLASS
def get_queryset(self):
"""
Get the list of items for this view.
This must be an iterable, and may be a queryset.
Defaults to using `self.queryset`.
This method should always be used rather than accessing `self.queryset`
directly, as `self.queryset` gets evaluated only once, and those results
are cached for all subsequent requests.
You may want to override this if you need to provide different
querysets depending on the incoming request.
(Eg. return a list of items that is specific to the user)
"""
# 断言查看当前实例 是否为 None
assert self.queryset is not None, (
"'%s' should either include a `queryset` attribute, "
"or override the `get_queryset()` method."
% self.__class__.__name__
)
# 获取当前实例
queryset = self.queryset
# 判断类型是否为 isinstance
if isinstance(queryset, QuerySet):
# Ensure queryset is re-evaluated on each request.
queryset = queryset.all()
# 返回其结果
return queryset
def get_object(self):
"""
Returns the object the view is displaying.
You may want to override this if you need to provide non-standard
queryset lookups. Eg if objects are referenced using multiple
keyword arguments in the url conf.
"""
# 获取当前实例,并根据 filter_backends 进行条件筛选
queryset = self.filter_queryset(self.get_queryset())
# Perform the lookup filtering.
# 判断查询关键字 默认 pk
lookup_url_kwarg = self.lookup_url_kwarg or self.lookup_field
assert lookup_url_kwarg in self.kwargs, (
'Expected view %s to be called with a URL keyword argument '
'named "%s". Fix your URL conf, or set the `.lookup_field` '
'attribute on the view correctly.' %
(self.__class__.__name__, lookup_url_kwarg)
)
# 查询关键字
filter_kwargs = {self.lookup_field: self.kwargs[lookup_url_kwarg]}
# 获取不到则 404
obj = get_object_or_404(queryset, **filter_kwargs)
# May raise a permission denied
# 权限校验
self.check_object_permissions(self.request, obj)
return obj
def get_serializer(self, *args, **kwargs):
"""
Return the serializer instance that should be used for validating and
deserializing input, and for serializing output.
"""
# 获取当前序列化
serializer_class = self.get_serializer_class()
kwargs['context'] = self.get_serializer_context()
return serializer_class(*args, **kwargs)
def get_serializer_class(self):
"""
Return the class to use for the serializer.
Defaults to using `self.serializer_class`.
You may want to override this if you need to provide different
serializations depending on the incoming request.
(Eg. admins get full serialization, others get basic serialization)
"""
# 断言是否为 None
assert self.serializer_class is not None, (
"'%s' should either include a `serializer_class` attribute, "
"or override the `get_serializer_class()` method."
% self.__class__.__name__
)
return self.serializer_class
def get_serializer_context(self):
"""
Extra context provided to the serializer class.
"""
# 获取request以及参数
return {
'request': self.request,
'format': self.format_kwarg,
'view': self
}
def filter_queryset(self, queryset):
"""
Given a queryset, filter it with whichever filter backend is in use.
You are unlikely to want to override this method, although you may need
to call it either from a list view, or from a custom `get_object`
method if you want to apply the configured filtering backend to the
default queryset.
"""
# 根据条件去筛选数据
for backend in list(self.filter_backends):
queryset = backend().filter_queryset(self.request, queryset, self)
return queryset
@property
def paginator(self):
"""
The paginator instance associated with the view, or `None`.
"""
# 判断是否有分页方法
if not hasattr(self, '_paginator'):
if self.pagination_class is None:
self._paginator = None
else:
self._paginator = self.pagination_class()
return self._paginator
def paginate_queryset(self, queryset):
"""
Return a single page of results, or `None` if pagination is disabled.
"""
# 使用分页
if self.paginator is None:
return None
return self.paginator.paginate_queryset(queryset, self.request, view=self)
def get_paginated_response(self, data):
"""
Return a paginated style `Response` object for the given output data.
"""
# 断言是否为None
assert self.paginator is not None
# 分页返回数据
return self.paginator.get_paginated_response(data)GenericViewSet 的本质就是将 APIView与mixins 混合类进行封装,以便快速实现一些简单的业务逻辑。
使用技巧
class RoleModelViewSet(ModelViewSet):
# 查询集
queryset = Role.objects.all()
# 序列化
serializer_class = RoleModelSerializer
# 自定义分页
pagination_class = PageNum
# 条件过滤以及排序打开
filter_backends = (DjangoFilterBackend, OrderingFilter) # 同时支持过滤和排序
# 排序字段
ordering_fields = ('date_joined', 'id') # ?ordering=-id
# # 5.2指定过滤字段, 不设置, 过滤功能不起效
filter_fields = ('zh_name', 'name') # ?username = tom & phone = & is_active = true
"""
methods: 声明该action对应的请求方式,列表传递
detail: 声明该action的路径是否与单一资源对应,及是否是xxx/<pk>/action方法名/
True 表示路径格式是xxx/<pk>/action方法名/
False 表示路径格式是xxx/action方法名/
"""
# 自定义方法 get 请求
@action(methods=['get'], detail=False)
def unactived(self, request, *args, **kwargs):
# 获取查询集, 过滤出未激活的用户
qs = self.queryset.filter(is_active=False)
# 使用序列化器, 序列化查询集, 并且是
ser = self.get_serializer(qs, many=True)
return Response(ser.data)
# 重写 perform_update 方法,也就是在保存之前进行逻辑处理
def perform_update(self, serializer):
user_obj = serializer.save()
print(user_obj)
# 保存
print(self.request.data)
# 获取前端传过来的id
role_id = self.request.data.get("role")
# 反向查询
user_obj.role_user_set.all().delete()
for i in role_id:
print(i)
userrole = Role_User.objects.create(user=user_obj, role_id=i)
# 重写 get_serializer_class 方法,可以根据不同的请求选择不同的序列化器
def get_serializer_class(self):
# 添加时 使用这个序列化器
if self.action == "create":
return WorkOrderModelSerializer
elif self.action == "update":
return WorkOrderModelSerializer
elif self.action == "list":
return WorkOrderModelSerializer2
else:
return WorkOrderDeppModelSerializer觉得文章写的不错,可以请喝杯咖啡



- Post link: https://yanxiang.wang/Django%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90/
- Copyright Notice: All articles in this blog are licensed under unless otherwise stated.